from fastai.vision.all import *计算机视觉介绍
在计算机视觉中使用 fastai 库。
本教程重点介绍如何快速构建一个 Learner 并对预训练模型进行微调,以应用于大多数计算机视觉任务。
单标签分类
对于此任务,我们将使用包含 37 种不同品种猫和狗图像的 Oxford-IIIT Pet Dataset。我们将首先展示如何构建一个简单的猫狗分类器,然后构建一个更高级的模型来对所有品种进行分类。
可以使用以下代码行下载并解压数据集
path = untar_data(URLs.PETS)它只会下载一次,并返回解压后存档的位置。我们可以使用 .ls() 方法检查其中包含的内容。
path.ls()(#2) [Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images'),Path('/home/jhoward/.fastai/data/oxford-iiit-pet/annotations')]现在我们将忽略 annotations 文件夹,专注于 images 文件夹。get_image_files 是一个 fastai 函数,可以帮助我们获取一个文件夹中的所有图像文件(递归地)。
files = get_image_files(path/"images")
len(files)7390猫 vs 狗
为了标记猫狗问题的数据,我们需要知道哪些文件名是狗的图片,哪些是猫的图片。有一种简单的区分方法:猫的文件名以大写字母开头,狗的文件名以小写字母开头
files[0],files[6](Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/basset_hound_181.jpg'),
Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/beagle_128.jpg'))然后我们可以定义一个简单的标签函数
def label_func(f): return f[0].isupper()为了让我们的数据准备好用于模型,我们需要将其放入一个 DataLoaders 对象中。在这里,我们有一个使用文件名进行标记的函数,因此我们将使用 ImageDataLoaders.from_name_func。ImageDataLoaders 还有其他工厂方法可能更适合您的问题,请务必查看 vision.data 中的所有方法。
dls = ImageDataLoaders.from_name_func(path, files, label_func, item_tfms=Resize(224))我们向此函数传递了我们正在使用的目录、我们获取的 files、我们的 label_func 以及最后一个参数 item_tfms:这是一个应用于数据集所有项目的 Transform,它将通过对最大维度进行随机裁剪使其成为正方形,然后将其大小调整为 224x224,从而将每张图片调整为 224x224。如果我们不传递这个参数,稍后就会出错,因为无法将这些项目批量处理。
然后我们可以使用 show_batch 方法检查一切是否正常(True 表示猫,False 表示狗)
dls.show_batch()
然后我们可以创建一个 Learner,它是 fastai 对象,结合了数据和用于训练的模型,并使用迁移学习只需两行代码即可微调预训练模型
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)| 周期 | 训练损失 | 验证损失 | 错误率 | 时间 |
|---|---|---|---|---|
| 0 | 0.150819 | 0.023647 | 0.007442 | 00:09 |
| 周期 | 训练损失 | 验证损失 | 错误率 | 时间 |
|---|---|---|---|---|
| 0 | 0.046232 | 0.011466 | 0.004736 | 00:10 |
第一行代码下载了一个名为 ResNet34 的模型,它在 ImageNet 上进行了预训练,并将其调整以适应我们的特定问题。然后它对该模型进行了微调,在相对短的时间内,我们得到一个错误率远低于 1% 的模型……太棒了!
如果您想对新图像进行预测,可以使用 learn.predict
learn.predict(files[0])('False', TensorImage(0), TensorImage([9.9998e-01, 2.0999e-05]))predict 方法返回三样东西:解码后的预测结果(这里 False 代表狗)、预测类别的索引以及所有类别的概率张量(按照索引标签的顺序)(在这种情况下,模型对结果是狗非常有信心)。此方法在这种情况下接受文件名、PIL 图像或直接张量。我们还可以使用 show_results 方法查看一些预测结果
learn.show_results()
查看其他应用,例如文本或表格数据,或者本教程中涵盖的其他问题,您会发现它们都共享一致的 API 来收集数据和查看数据、创建 Learner、训练模型以及查看一些预测结果。
分类品种
为了用品种名称标记我们的数据,我们将使用正则表达式从文件名中提取它。回看文件名,我们有
files[0].name'great_pyrenees_173.jpg'因此,类别是最后一个 _ 后面跟着一些数字之前的所有内容。因此,可以捕获名称的正则表达式是
pat = r'^(.*)_\d+.jpg'由于使用正则表达式标记数据非常常见(通常标签隐藏在文件名中),因此有一个工厂方法可以做到这一点
dls = ImageDataLoaders.from_name_re(path, files, pat, item_tfms=Resize(224))和之前一样,我们可以使用 show_batch 查看我们的数据
dls.show_batch()
由于在 37 个不同品种的猫狗中对确切品种进行分类是一个更难的问题,我们将稍微修改 DataLoaders 的定义,以使用数据增强
dls = ImageDataLoaders.from_name_re(path, files, pat, item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224))这次我们在批量处理之前调整了大小,并添加了 batch_tfms。aug_transforms 是一个函数,提供了一系列数据增强变换,其默认设置在许多数据集上表现良好。您可以通过向 aug_transforms 传递适当的参数来定制这些变换。
dls.show_batch()
然后我们可以像之前一样创建我们的 Learner 并训练我们的模型。
learn = vision_learner(dls, resnet34, metrics=error_rate)我们之前使用了默认学习率,但我们可能想找到最好的学习率。为此,我们可以使用学习率查找器
learn.lr_find()SuggestedLRs(lr_min=0.010000000149011612, lr_steep=0.0063095735386013985)
它绘制了学习率查找器的图表,并给了我们两个建议(最小值除以 10 和最陡梯度)。我们在这里使用 3e-3。我们还将进行更多的周期
learn.fine_tune(2, 3e-3)| 周期 | 训练损失 | 验证损失 | 错误率 | 时间 |
|---|---|---|---|---|
| 0 | 1.270041 | 0.308686 | 0.109608 | 00:16 |
| 周期 | 训练损失 | 验证损失 | 错误率 | 时间 |
|---|---|---|---|---|
| 0 | 0.468626 | 0.355379 | 0.117050 | 00:21 |
| 1 | 0.418402 | 0.384385 | 0.110961 | 00:20 |
| 2 | 0.267954 | 0.220428 | 0.075778 | 00:21 |
| 3 | 0.143201 | 0.203174 | 0.064953 | 00:20 |
同样,我们可以使用 show_results 查看一些预测结果
learn.show_results()
另一个有用的东西是解释对象,它可以向我们展示模型在哪里做出了最差的预测
interp = Interpretation.from_learner(learn)interp.plot_top_losses(9, figsize=(15,10))
单标签分类 - 使用数据块 API
我们还可以使用数据块 API 将数据放入 DataLoaders 中。这有点更高级,如果您还不适应学习新 API,请随时跳过这部分。
数据块是通过向 fastai 库提供一系列信息来构建的
- 使用的类型,通过一个名为
blocks的参数:这里我们有图像和类别,所以我们传递ImageBlock和CategoryBlock。 - 如何获取原始项目,这里是我们的函数
get_image_files。 - 如何标记这些项目,这里使用和之前相同的正则表达式。
- 如何分割这些项目,这里使用随机分割器。
- 和之前一样的
item_tfms和batch_tfms。
pets = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224))pets 对象本身是空的:它只包含帮助我们收集数据的函数。我们必须调用 dataloaders 方法来获取 DataLoaders。我们将数据源传递给它
dls = pets.dataloaders(untar_data(URLs.PETS)/"images")然后我们可以使用 dls.show_batch() 查看我们的一些图片
dls.show_batch(max_n=9)
多标签分类
对于此任务,我们将使用包含不同种类对象/人物图像的 Pascal Dataset。它最初是用于对象检测的数据集,这意味着任务不仅是检测图像中是否存在某个类别的实例,还要在其周围绘制一个边界框。在这里,我们将只尝试预测给定图像中的所有类别。
多标签分类与之前不同之处在于,每张图像不只属于一个类别。例如,一张图像中可能同时包含一个人和一匹马。或者不包含我们研究的任何类别。
和之前一样,我们可以很轻松地下载数据集
path = untar_data(URLs.PASCAL_2007)
path.ls()(#9) [Path('/home/jhoward/.fastai/data/pascal_2007/valid.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test'),Path('/home/jhoward/.fastai/data/pascal_2007/train.json'),Path('/home/jhoward/.fastai/data/pascal_2007/test.csv'),Path('/home/jhoward/.fastai/data/pascal_2007/models'),Path('/home/jhoward/.fastai/data/pascal_2007/segmentation'),Path('/home/jhoward/.fastai/data/pascal_2007/train.csv'),Path('/home/jhoward/.fastai/data/pascal_2007/train')]每张图像的标签信息都在名为 train.csv 的文件中。我们使用 pandas 加载它
df = pd.read_csv(path/'train.csv')
df.head()| 文件名 | 标签 | 是否有效 | |
|---|---|---|---|
| 0 | 000005.jpg | 椅子 | True |
| 1 | 000007.jpg | 汽车 | True |
| 2 | 000009.jpg | 马 人 | True |
| 3 | 000012.jpg | 汽车 | False |
| 4 | 000016.jpg | 自行车 | True |
多标签分类 - 使用高级 API
这很直接:对于每个文件名,我们获得不同的标签(用空格分隔),最后一列指示它是否在验证集中。为了快速将其放入 DataLoaders 中,我们有一个工厂方法 from_df。我们可以指定所有图像所在的底层路径,在基础路径和文件名之间添加一个附加文件夹(此处为 train),用于验证集的 valid_col(如果我们不指定它,我们将选取一个随机子集),用于分割标签的 label_delim,以及和之前一样的 item_tfms 和 batch_tfms。
注意,我们不必指定 fn_col 和 label_col,因为它们默认分别是第一列和第二列。
dls = ImageDataLoaders.from_df(df, path, folder='train', valid_col='is_valid', label_delim=' ',
item_tfms=Resize(460), batch_tfms=aug_transforms(size=224))和之前一样,我们可以使用 show_batch 方法查看数据。
dls.show_batch()
训练模型像之前一样简单:可以应用相同的函数,fastai 库会自动检测到我们处于多标签问题,从而选择正确的损失函数。唯一的区别在于我们传递的度量:error_rate 不适用于多标签问题,但我们可以使用 accuracy_thresh 和 F1ScoreMulti。我们还可以更改度量的默认名称,例如,我们可能希望查看使用 macro 和 samples 平均值的 F1 分数。
f1_macro = F1ScoreMulti(thresh=0.5, average='macro')
f1_macro.name = 'F1(macro)'
f1_samples = F1ScoreMulti(thresh=0.5, average='samples')
f1_samples.name = 'F1(samples)'
learn = vision_learner(dls, resnet50, metrics=[partial(accuracy_multi, thresh=0.5), f1_macro, f1_samples])和之前一样,我们可以使用 learn.lr_find 来选择一个好的学习率
learn.lr_find()SuggestedLRs(lr_min=0.025118863582611083, lr_steep=0.03981071710586548)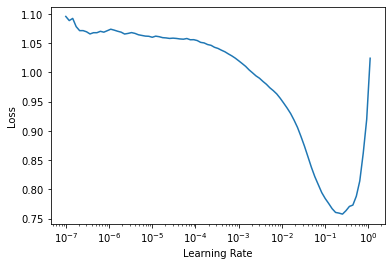
我们可以选择建议的学习率并微调我们的预训练模型
learn.fine_tune(2, 3e-2)| 周期 | 训练损失 | 验证损失 | 多标签准确率 | 时间 |
|---|---|---|---|---|
| 0 | 0.437855 | 0.136942 | 0.954801 | 00:17 |
| 周期 | 训练损失 | 验证损失 | 多标签准确率 | 时间 |
|---|---|---|---|---|
| 0 | 0.156202 | 0.465557 | 0.914801 | 00:20 |
| 1 | 0.179814 | 0.382907 | 0.930040 | 00:20 |
| 2 | 0.157007 | 0.129412 | 0.953924 | 00:20 |
| 3 | 0.125787 | 0.109033 | 0.960856 | 00:19 |
和之前一样,我们可以轻松查看结果
learn.show_results()
或者获取给定图像的预测结果
learn.predict(path/'train/000005.jpg')((#2) ['chair','diningtable'],
TensorImage([False, False, False, False, False, False, False, False, True, False,
True, False, False, False, False, False, False, False, False, False]),
TensorImage([1.6750e-03, 5.3663e-03, 1.6378e-03, 2.2269e-03, 5.8645e-02, 6.3422e-03,
5.6991e-03, 1.3682e-02, 8.6864e-01, 9.7093e-04, 6.4747e-01, 4.1217e-03,
1.2410e-03, 2.9412e-03, 4.7769e-01, 9.9664e-02, 4.5190e-04, 6.3532e-02,
6.4487e-03, 1.6339e-01]))与单标签分类预测一样,我们得到三样东西。最后一个是模型对每个类别的预测(范围从 0 到 1)。倒数第二个对应于一个独热编码的目标(对于所有预测的类别,即概率 > 0.5 的类别,您会得到 True),第一个是解码后的可读版本。
和之前一样,我们可以检查模型在哪里做得最差
interp = Interpretation.from_learner(learn)
interp.plot_top_losses(9)| 目标 | 预测结果 | 概率 | 损失 | |
|---|---|---|---|---|
| 0 | 汽车;人;电视显示器 | 汽车 | tensor([7.2388e-12, 5.9609e-06, 1.7054e-11, 3.8985e-09, 7.7078e-12, 3.4044e-07,\n 9.9999e-01, 7.2118e-12, 1.0105e-05, 3.1035e-09, 2.3334e-09, 9.1077e-09,\n 1.6201e-09, 1.1083e-08, 1.0809e-02, 2.1072e-07, 9.5961e-16, 5.0478e-07,\n 4.4531e-10, 9.6444e-12]) | 1.494603157043457 |
| 1 | 船 | 汽车 | tensor([8.3430e-06, 1.9416e-03, 6.9865e-06, 1.2985e-04, 1.6142e-06, 8.2200e-05,\n 9.9698e-01, 1.3143e-06, 1.0047e-03, 4.9794e-05, 1.9155e-05, 4.7409e-05,\n 7.5056e-05, 1.6572e-05, 3.4760e-02, 6.9266e-04, 1.3006e-07, 6.0702e-04,\n 1.5781e-05, 1.9860e-06]) | 0.7395917773246765 |
| 2 | 公共汽车;汽车 | 汽车 | tensor([2.2509e-11, 1.0772e-05, 6.0177e-11, 4.8728e-09, 1.7920e-11, 4.8695e-07,\n 9.9999e-01, 9.0638e-12, 1.9819e-05, 8.8023e-09, 5.1272e-09, 2.3535e-08,\n 6.0401e-09, 7.2609e-09, 4.4117e-03, 4.8268e-07, 1.2528e-14, 1.2667e-06,\n 8.2282e-10, 1.6300e-11]) | 0.7269787192344666 |
| 3 | 椅子;餐桌;人 | 人;火车 | tensor([1.6638e-03, 2.0881e-02, 4.7525e-03, 2.6422e-02, 6.2972e-04, 4.7170e-02,\n 1.2263e-01, 2.9744e-03, 5.5352e-03, 7.1830e-03, 1.0062e-03, 2.6123e-03,\n 1.8208e-02, 5.9618e-02, 7.6859e-01, 3.3504e-03, 1.1324e-03, 2.3881e-03,\n 6.5440e-01, 1.7040e-03]) | 0.6879587769508362 |
| 4 | 船;椅子;餐桌;人 | 人 | tensor([0.0058, 0.0461, 0.0068, 0.1083, 0.0094, 0.0212, 0.4400, 0.0047, 0.0166,\n 0.0054, 0.0030, 0.0258, 0.0020, 0.0800, 0.5880, 0.0147, 0.0026, 0.1440,\n 0.0219, 0.0166]) | 0.6826764941215515 |
| 5 | 自行车;汽车;人 | 汽车 | tensor([3.6825e-09, 7.3755e-05, 1.7181e-08, 4.5056e-07, 3.5667e-09, 1.0882e-05,\n 9.9939e-01, 6.0704e-09, 5.7179e-05, 3.8519e-07, 9.3825e-08, 6.1463e-07,\n 3.9191e-07, 2.6800e-06, 3.3091e-02, 3.1972e-06, 2.6873e-11, 1.1967e-05,\n 1.1480e-07, 3.3320e-09]) | 0.6461981534957886 |
| 6 | 瓶子;牛;人 | 椅子;人;沙发 | tensor([5.4520e-04, 4.2805e-03, 2.3828e-03, 1.4127e-03, 4.5856e-02, 3.5540e-03,\n 9.1525e-03, 2.9113e-02, 6.9326e-01, 1.0407e-03, 7.0658e-02, 3.1101e-02,\n 2.4843e-03, 2.9908e-03, 8.8695e-01, 2.2719e-01, 1.0283e-03, 6.0414e-01,\n 1.3598e-03, 5.7382e-02]) | 0.6329519152641296 |
| 7 | 椅子;狗;人 | 猫 | tensor([3.4073e-05, 1.3574e-03, 7.0516e-04, 1.9189e-04, 6.0819e-03, 4.7242e-05,\n 9.6424e-04, 9.3669e-01, 9.0736e-02, 8.1472e-04, 1.1019e-02, 5.4633e-02,\n 2.6190e-04, 1.4943e-04, 1.2755e-02, 1.7530e-02, 2.2532e-03, 2.2129e-02,\n 1.5532e-04, 6.6390e-03]) | 0.6249645352363586 |
| 8 | 汽车;人;盆栽 | 汽车 | tensor([1.3978e-06, 2.1693e-03, 2.2698e-07, 7.5037e-05, 9.4007e-07, 1.2369e-03,\n 9.9919e-01, 1.0879e-07, 3.1837e-04, 1.8340e-05, 7.5422e-06, 2.3891e-05,\n 2.5957e-05, 3.0890e-05, 8.4529e-02, 2.0280e-04, 4.1234e-09, 1.7978e-04,\n 2.3258e-05, 6.0897e-07]) | 0.5489450693130493 |

多标签分类 - 使用数据块 API
我们还可以使用数据块 API 将数据放入 DataLoaders 中。就像我们之前说的,如果您还不适应学习新 API,请随时跳过这部分。
记住我们的数据在数据框中的结构是怎样的
df.head()| 文件名 | 标签 | 是否有效 | |
|---|---|---|---|
| 0 | 000005.jpg | 椅子 | True |
| 1 | 000007.jpg | 汽车 | True |
| 2 | 000009.jpg | 马 人 | True |
| 3 | 000012.jpg | 汽车 | False |
| 4 | 000016.jpg | 自行车 | True |
在这种情况下,我们通过提供以下信息来构建数据块
- 使用的类型:
ImageBlock和MultiCategoryBlock。 - 如何从数据框中获取输入项目:这里我们读取列
fname,需要在开头添加 path/train/ 以获得正确的文件名。 - 如何从数据框中获取目标:这里我们读取列
labels,需要按空格分割。 - 如何分割项目,这里使用列
is_valid。 - 和之前一样的
item_tfms和batch_tfms。
pascal = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=ColSplitter('is_valid'),
get_x=ColReader('fname', pref=str(path/'train') + os.path.sep),
get_y=ColReader('labels', label_delim=' '),
item_tfms = Resize(460),
batch_tfms=aug_transforms(size=224))这个数据块和之前略有不同:我们不需要传递一个函数来收集所有项目,因为我们将提供的数据框已经包含了所有项目。但是,我们需要预处理数据框的行以获取我们的输入,这就是我们传递 get_x 的原因。它默认为 fastai 函数 noop,这也是我们之前不需要传递它的原因。
和之前一样,pascal 只是一个蓝图。我们需要将数据源传递给它,才能获取 DataLoaders
dls = pascal.dataloaders(df)然后我们可以使用 dls.show_batch() 查看我们的一些图片
dls.show_batch(max_n=9)
分割
分割是一个需要预测图像中每个像素所属类别的问题。对于此任务,我们将使用 Camvid 数据集,这是一个来自车载摄像头截图的数据集。图像中的每个像素都有一个标签,例如“道路”、“汽车”或“行人”。
像往常一样,我们可以使用 untar_data 函数下载数据。
path = untar_data(URLs.CAMVID_TINY)
path.ls()(#3) [Path('/home/jhoward/.fastai/data/camvid_tiny/codes.txt'),Path('/home/jhoward/.fastai/data/camvid_tiny/images'),Path('/home/jhoward/.fastai/data/camvid_tiny/labels')]images 文件夹包含图像,相应的标签分割掩码在 labels 文件夹中。codes 文件包含对应的整数到类别映射(掩码中每个像素都有一个整数值)。
codes = np.loadtxt(path/'codes.txt', dtype=str)
codesarray(['Animal', 'Archway', 'Bicyclist', 'Bridge', 'Building', 'Car',
'CartLuggagePram', 'Child', 'Column_Pole', 'Fence', 'LaneMkgsDriv',
'LaneMkgsNonDriv', 'Misc_Text', 'MotorcycleScooter', 'OtherMoving',
'ParkingBlock', 'Pedestrian', 'Road', 'RoadShoulder', 'Sidewalk',
'SignSymbol', 'Sky', 'SUVPickupTruck', 'TrafficCone',
'TrafficLight', 'Train', 'Tree', 'Truck_Bus', 'Tunnel',
'VegetationMisc', 'Void', 'Wall'], dtype='<U17')分割 - 使用高级 API
和之前一样,get_image_files 函数帮助我们获取所有图像文件名
fnames = get_image_files(path/"images")
fnames[0]Path('/home/jhoward/.fastai/data/camvid_tiny/images/0006R0_f02910.png')让我们看看 labels 文件夹里有什么
(path/"labels").ls()[0]Path('/home/jhoward/.fastai/data/camvid_tiny/labels/0016E5_08137_P.png')看来分割掩码与图像具有相同的基本名称,但多了一个 _P,所以我们可以定义一个标签函数
def label_func(fn): return path/"labels"/f"{fn.stem}_P{fn.suffix}"然后我们可以使用 SegmentationDataLoaders 收集我们的数据
dls = SegmentationDataLoaders.from_label_func(
path, bs=8, fnames = fnames, label_func = label_func, codes = codes
)我们在这里不需要传递 item_tfms 来调整图像大小,因为它们都已经具有相同的大小。
像往常一样,我们可以使用 show_batch 方法查看我们的数据。在此示例中,fastai 库正在将掩码与每个像素的特定颜色叠加
dls.show_batch(max_n=6)
传统的 CNN 不适用于分割,我们必须使用一种称为 UNet 的特殊模型,所以我们使用 unet_learner 来定义我们的 Learner
learn = unet_learner(dls, resnet34)
learn.fine_tune(6)| 周期 | 训练损失 | 验证损失 | 时间 |
|---|---|---|---|
| 0 | 2.802264 | 2.476579 | 00:03 |
| 周期 | 训练损失 | 验证损失 | 时间 |
|---|---|---|---|
| 0 | 1.664625 | 1.525224 | 00:03 |
| 1 | 1.440311 | 1.271917 | 00:02 |
| 2 | 1.339473 | 1.123384 | 00:03 |
| 3 | 1.233049 | 0.988725 | 00:03 |
| 4 | 1.110815 | 0.805028 | 00:02 |
| 5 | 1.008600 | 0.815411 | 00:03 |
| 6 | 0.924937 | 0.755052 | 00:02 |
| 7 | 0.857789 | 0.769288 | 00:03 |
和之前一样,我们可以使用 show_results 了解预测结果
learn.show_results(max_n=6, figsize=(7,8))
我们还可以使用 SegmentationInterpretation 类对模型在验证集上的错误进行排序,然后绘制对验证损失贡献最高的 k 个实例。
interp = SegmentationInterpretation.from_learner(learn)
interp.plot_top_losses(k=3)
分割 - 使用数据块 API
我们还可以使用数据块 API 将数据放入 DataLoaders 中。就像之前说过的,如果您还不适应学习新 API,请随时跳过这部分。
在这种情况下,我们通过提供以下信息来构建数据块
- 使用的类型:
ImageBlock和MaskBlock。我们将codes提供给MaskBlock,因为无法从数据中推断出它们。 - 如何收集我们的项目,这里使用
get_image_files。 - 如何从我们的项目中获取目标:使用
label_func。 - 如何分割项目,这里是随机分割。
- 用于数据增强的
batch_tfms。
camvid = DataBlock(blocks=(ImageBlock, MaskBlock(codes)),
get_items = get_image_files,
get_y = label_func,
splitter=RandomSplitter(),
batch_tfms=aug_transforms(size=(120,160)))dls = camvid.dataloaders(path/"images", path=path, bs=8)dls.show_batch(max_n=6)
点
本节使用了数据块 API,所以如果您之前跳过了它,我们也建议您跳过本节。
现在我们将看看一个任务,即预测图片中的点。为此,我们将使用 Biwi Kinect Head Pose 数据集。首先,像往常一样下载数据集。
path = untar_data(URLs.BIWI_HEAD_POSE)让我们看看我们有什么!
path.ls()(#50) [Path('/home/sgugger/.fastai/data/biwi_head_pose/01.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/18.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/04'),Path('/home/sgugger/.fastai/data/biwi_head_pose/10.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/24'),Path('/home/sgugger/.fastai/data/biwi_head_pose/14.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/20.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/11.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/02.obj'),Path('/home/sgugger/.fastai/data/biwi_head_pose/07')...]有 24 个目录,编号从 01 到 24(它们对应于不同的被拍摄者)以及一个相应的 .obj 文件(我们在这里不需要它们)。我们将查看其中一个目录
(path/'01').ls()(#1000) [Path('01/frame_00087_pose.txt'),Path('01/frame_00079_pose.txt'),Path('01/frame_00114_pose.txt'),Path('01/frame_00084_rgb.jpg'),Path('01/frame_00433_pose.txt'),Path('01/frame_00323_rgb.jpg'),Path('01/frame_00428_rgb.jpg'),Path('01/frame_00373_pose.txt'),Path('01/frame_00188_rgb.jpg'),Path('01/frame_00354_rgb.jpg')...]在子目录中,我们有不同的帧,每个帧都带有一个图像 (\_rgb.jpg) 和一个姿态文件 (\_pose.txt)。我们可以轻松地使用 get_image_files 递归地获取所有图像文件,然后编写一个函数,将图像文件名转换为其关联的姿态文件。
img_files = get_image_files(path)
def img2pose(x): return Path(f'{str(x)[:-7]}pose.txt')
img2pose(img_files[0])Path('04/frame_00084_pose.txt')我们可以看看我们的第一张图片
im = PILImage.create(img_files[0])
im.shape(480, 640)im.to_thumb(160)
Biwi 数据集网站解释了与每张图像关联的姿态文本文件格式,其中显示了头部中心的位置。这些细节对于我们的目的不重要,所以我们只展示用于提取头部中心点的函数
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6)
def get_ctr(f):
ctr = np.genfromtxt(img2pose(f), skip_header=3)
c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2]
c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2]
return tensor([c1,c2])此函数将坐标作为包含两个元素的张量返回
get_ctr(img_files[0])tensor([372.4046, 245.8602])我们可以将此函数作为 get_y 传递给 DataBlock,因为它负责标记每个项目。我们将图像大小调整为其输入大小的一半,只是为了稍微加快训练速度。
需要注意的一点是,我们不应仅仅使用随机分割器。原因在于同一个人物在该数据集中出现在多张图像中——但我们希望确保我们的模型能够泛化到它尚未见过的人物。数据集中的每个文件夹包含一个人物的图像。因此,我们可以创建一个分割函数,该函数仅对一个人返回 true,从而生成一个只包含该人物图像的验证集。
与之前的数据块示例唯一不同之处在于,第二个块是 PointBlock。这是必需的,以便 fastai 知道标签表示坐标;这样,它就知道在进行数据增强时,应将相同的增强应用于这些坐标,就像应用于图像一样。
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name=='13'),
batch_tfms=[*aug_transforms(size=(240,320)),
Normalize.from_stats(*imagenet_stats)]
)dls = biwi.dataloaders(path)
dls.show_batch(max_n=9, figsize=(8,6))
现在我们已经组装了数据,我们可以像往常一样使用 fastai API 的其余部分。vision_learner 在这种情况下完美工作,并且库将从数据中推断出合适的损失函数
learn = vision_learner(dls, resnet18, y_range=(-1,1))learn.lr_find()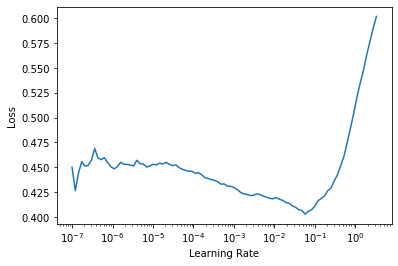
然后我们可以训练我们的模型
learn.fine_tune(1, 5e-3)| 周期 | 训练损失 | 验证损失 | 时间 |
|---|---|---|---|
| 0 | 0.057434 | 0.002171 | 00:31 |
| 周期 | 训练损失 | 验证损失 | 时间 |
|---|---|---|---|
| 0 | 0.005320 | 0.005426 | 00:39 |
| 1 | 0.003624 | 0.000698 | 00:39 |
| 2 | 0.002163 | 0.000099 | 00:39 |
| 3 | 0.001325 | 0.000233 | 00:39 |
损失是均方误差,这意味着我们平均犯错
math.sqrt(0.0001)0.01百分比,当我们预测点时!我们可以像往常一样查看这些结果
learn.show_results()