model = nn.Sequential(nn.Linear(10,30), nn.BatchNorm1d(30), nn.Linear(30,2)).cuda()
model = convert_network(model, torch.float16)
for i,t in enumerate([torch.float16, torch.float32, torch.float16]):
test_eq(model[i].weight.dtype, t)
test_eq(model[i].bias.dtype, t)
model = nn.Sequential(nn.Linear(10,30), BatchNorm(30, ndim=1), nn.Linear(30,2)).cuda()
model = convert_network(model, torch.float16)
for i,t in enumerate([torch.float16, torch.float32, torch.float16]):
test_eq(model[i].weight.dtype, t)
test_eq(model[i].bias.dtype, t)混合精度训练
支持混合精度训练的回调和工具函数
理论基础
一篇非常棒且清晰的混合精度训练介绍是 NVIDIA 的这个视频。
什么是半精度?
在神经网络中,所有计算通常都在单精度下进行,这意味着所有表示输入、激活、权重等数组中的浮点数都是 32 位浮点数(在本文其余部分称为 FP32)。一种减少内存使用(并避免那些恼人的 cuda 错误)的想法是尝试在半精度下做同样的事情,这意味着使用 16 位浮点数(或在本文其余部分称为 FP16)。根据定义,它们占用一半的内存空间,理论上可以让你将模型大小和批次大小翻倍。
另一个非常好的特性是 NVIDIA 开发了其最新的 GPU(Volta 架构),以充分利用半精度张量。基本上,如果你给这些 GPU 半精度张量,它们会堆叠这些张量,使得每个核心可以同时进行更多操作,理论上可以实现 8 倍的加速(可惜,只是理论上)。
因此,半精度训练对内存使用更好,如果你有 Volta GPU,速度会快得多(即使没有,计算更容易,速度也会稍微快一点)。我们怎么做呢?在 PyTorch 中超级简单,我们只需要在所有地方加上 .half():模型的输入和所有参数上。问题是最终通常看不到相同的精度(所以有时会发生),因为半精度……好吧……没那么精确;)。
半精度的问题
为了理解半精度的问题,让我们简单看看 FP16 是什么样子(更多信息在此)。
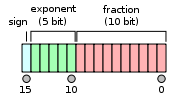
符号位给出 +1 或 -1,然后我们有 5 位来编码介于 -14 和 15 之间的指数,而小数部分有剩余的 10 位。与 FP32 相比,我们有更小的取值范围(大约 2e-14 到 2e15,而 FP32 是 2e-126 到 2e127),但偏移量也更小。
例如,在 1 和 2 之间,FP16 格式只表示数字 1, 1+2e-10, 1+2*2e-10… 这意味着在半精度下 1 + 0.0001 = 1。这会导致一些问题,特别是三个可能出现并扰乱你的训练的问题。
权重更新不精确:在你的优化器内部,你基本上对网络中的每个权重执行 w = w - lr * w.grad 操作。在半精度下执行此操作的问题在于,w.grad 通常比 w 小几个数量级,并且学习率也很小。因此,w=1 且 lr*w.grad 为 0.0001(或更低)的情况非常常见,但在这些情况下更新不起作用。
你的梯度可能发生下溢。在 FP16 中,你的梯度由于太小很容易被替换为 0。
你的激活值或损失值可能发生上溢。与梯度的问题相反:在 FP16 精度下更容易出现 nan(或无穷大),你的训练可能更容易发散。
解决方案:混合精度训练
为了解决这三个问题,我们不完全在 FP16 精度下训练。正如混合训练的名称所示,有些操作在 FP16 中进行,有些在 FP32 中进行。这主要是为了解决上面列出的第一个问题。对于接下来的两个问题,还有额外的技巧。
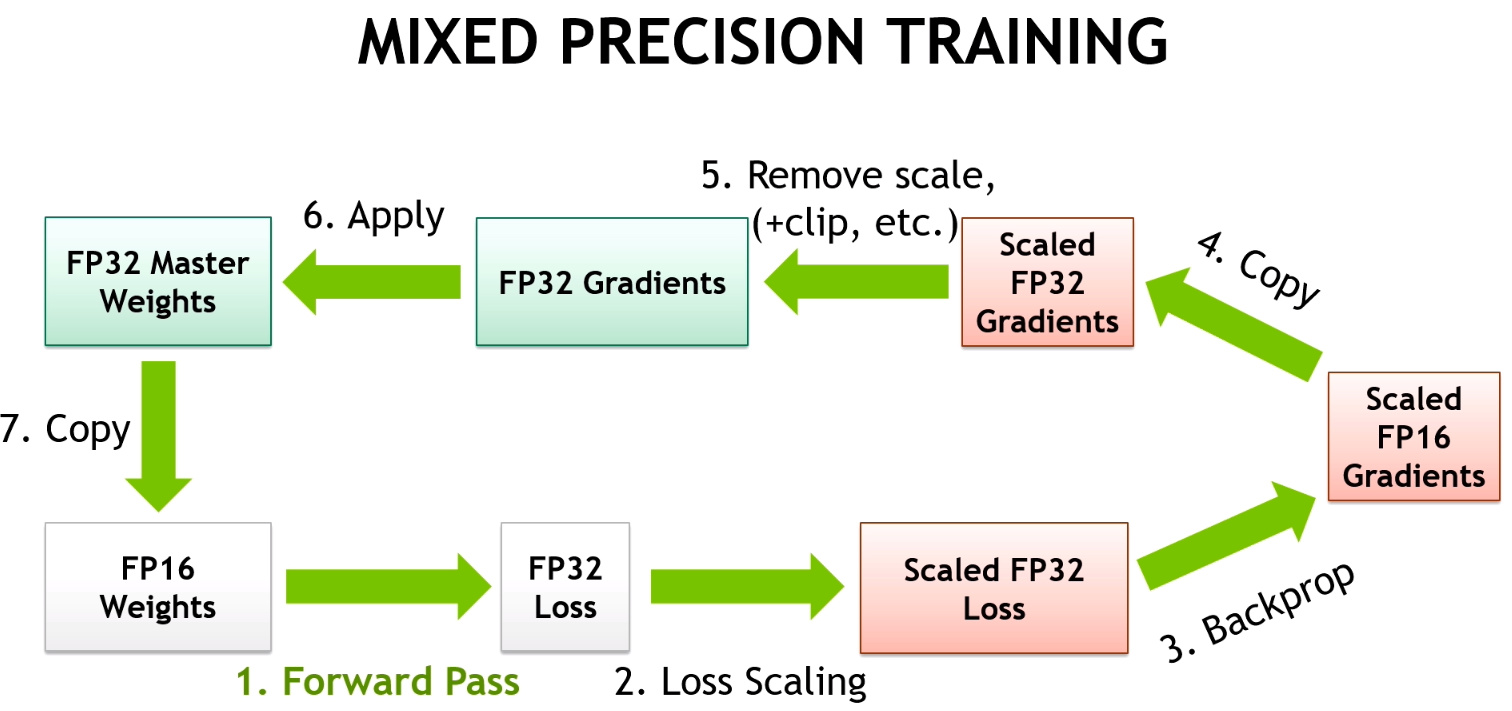
主要思想是,我们希望在前向传播和梯度计算中使用半精度(为了提高速度),但在更新时使用单精度(为了提高精度)。w 和 grad 都是半精度浮点数没问题,但当我们执行操作 w = w - lr * grad 时,我们需要在 FP32 中计算它。这样我们的 1 + 0.0001 就会变成 1.0001。
这就是为什么我们在 FP32 中保留权重的副本(称为主模型)。然后,我们的训练循环将看起来像这样:
- 使用 FP16 模型计算输出,然后计算损失
- 在半精度下反向传播梯度。
- 将梯度复制到 FP32 精度
- 在主模型上执行更新(在 FP32 精度下)
- 将主模型复制回 FP16 模型。
注意,我们在步骤 5 中会损失精度,某个权重的 1.0001 会变回 1。但是如果下一次更新再次对应于加上 0.0001,由于优化器步骤是在主模型上进行的,1.0001 将变成 1.0002,如果我们最终这样一直加到 1.0005,FP16 模型就能够分辨出差异。
这解决了问题 1。对于第二个问题,我们使用一种称为梯度缩放的技术:为了避免梯度因 FP16 精度而被置零,我们将损失乘以一个缩放因子(例如 scale=512)。这样我们就可以在下图中将梯度推向右边,使它们不会变成零。
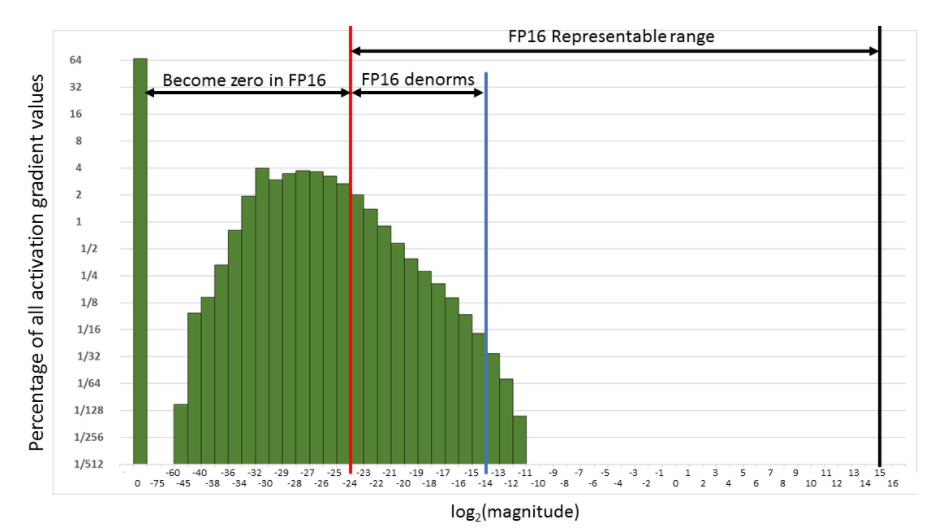
当然,我们不希望这些经过 512 倍缩放的梯度参与权重更新,所以在将它们转换为 FP32 后,我们可以将它们除以这个缩放因子(一旦它们没有变为 0 的风险)。这将循环改变为:
- 使用 FP16 模型计算输出,然后计算损失。
- 将损失乘以缩放因子,然后在半精度下反向传播梯度。
- 将梯度复制到 FP32 精度,然后将它们除以缩放因子。
- 在主模型上执行更新(在 FP32 精度下)。
- 将主模型复制回 FP16 模型。
对于最后一个问题,NVIDIA 提供的技巧是将 BatchNorm 层保留在单精度(它们的权重不多,所以内存压力不大),并在单精度下计算损失(这意味着在将模型的最后输出传递给损失函数之前将其转换为单精度)。
动态损失缩放
之前实现的混合精度训练唯一令人恼火的是引入了一个新的超参数需要调整,即损失缩放的值。对我们来说幸运的是,有办法解决这个问题。我们希望损失缩放值尽可能高,以便我们的梯度可以使用完整的表示范围,所以我们首先尝试一个非常高的值。很可能这将导致我们的梯度或损失溢出,然后我们将再次尝试一半的值,如此反复,直到找到不会导致梯度溢出的最大可能损失缩放值。
这个值将完美地适合我们的模型,并且随着训练的进行可以继续动态调整,如果它仍然太高,每次溢出时只需将其减半。然而,一段时间后,训练会收敛,梯度会开始变小,因此我们也需要一种机制,在安全的情况下增大这个动态损失缩放值。Apex 库中使用的策略是,每次在给定数量的迭代中没有溢出时,将损失缩放值乘以 2。
BFloat16 混合精度
BFloat16 (BF16) 是 Google Brain 开发的一种 16 位浮点格式。BF16 的指数与 FP32 相同,剩下 7 位用于表示小数。这使得 BF16 具有与 FP32 相同的范围,但精度显著较低。
由于它与 FP32 具有相同的范围,BF16 混合精度训练跳过了缩放步骤。所有其他混合精度步骤与 FP16 混合精度相同。
BF16 混合精度需要 Ampere 或更新的硬件。并非所有 PyTorch 操作都受支持。
要在 BF16 混合精度下训练,请将 amp_mode=AMPMode.BF16 或 amp_mode='bf16' 传递给MixedPrecision,或使用Learner.to_bf16 便利方法。
AMPMode
AMPMode (*values)
自动混合精度模式以便于完成
MixedPrecision
MixedPrecision (amp_mode:str|AMPMode=<AMPMode.FP16: 'fp16'>, init_scale:float=65536.0, growth_factor:float=2.0, backoff_factor:float=0.5, growth_interval:int=2000, enabled:bool=True)
使用 PyTorch 自动混合精度 (AMP) 的混合精度训练
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| amp_mode | str | main.AMPMode | AMPMode.FP16 | 混合精度训练模式。支持 fp16 和 bf16。 |
| init_scale | float | 65536.0 | |
| growth_factor | float | 2.0 | |
| backoff_factor | float | 0.5 | |
| growth_interval | int | 2000 | |
| enabled | bool | True |
Learner.to_fp16
Learner.to_fp16 (init_scale:float=65536.0, growth_factor:float=2.0, backoff_factor:float=0.5, growth_interval:int=2000, enabled:bool=True)
使用 PyTorch AMP 将Learner设置为 float16 混合精度
Learner.to_bf16
Learner.to_bf16 ()
使用 PyTorch AMP 将Learner设置为 bfloat16 混合精度
Learner.to_fp32
Learner.to_fp32 ()
将Learner设置为 float32 精度
工具函数
在介绍主Callback之前,我们需要一些辅助函数。我们使用APEX 库中的函数。
将模型转换为 FP16
我们需要一个函数来将模型的所有层转换为 FP16 精度,但 BatchNorm 类型的层除外(因为这些层需要在 FP32 精度下才能稳定)。在 Apex 中,为我们执行此操作的函数是 convert_network。我们可以使用它将模型设置为 FP16 或恢复到 FP32。
创建参数的主副本
从我们的模型参数(大部分是 FP16),我们将创建一个 FP32 副本(主参数),用于优化器中的步骤。可以选择将所有参数连接成一个大的扁平张量,这可以使该步骤稍微快一点。
我们不能在这里使用 FP16 工具函数,因为它无法处理多个参数组,而参数组是我们用于以下目的的:
- 进行迁移学习并冻结某些层
- 应用差异化学习率
- 不对某些层(如 BatchNorm)或偏置项应用权重衰减
get_master
get_master (opt:fastai.optimizer.Optimizer, flat_master:bool=False)
给定一个初始化的Optimizer,创建 fp16 模型参数,并返回 fp32 模型参数。
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| opt | Optimizer | 从中检索模型参数的优化器 | |
| flat_master | bool | False | 将 fp32 参数展平为向量以获得更好性能 |
| 返回 | list | fp16 参数列表和 fp32 参数列表 |
将梯度从模型参数复制到主参数
反向传播后,所有梯度必须复制到主参数,然后才能在 FP32 中执行优化器步骤。Apex 工具中的对应函数是 model_grads_to_master_grads,但我们需要对其进行调整以使其适用于参数组。
to_master_grads
to_master_grads (model_pgs:list, master_pgs:list, flat_master:bool=False)
将 fp16 模型梯度移动到 fp32 主梯度
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| model_pgs | list | 用于复制梯度的 fp16 模型参数 | |
| master_pgs | list | 用于复制梯度的 fp32 模型参数 | |
| flat_master | bool | False | fp32 参数之前是否被展平 |
将主参数复制到模型参数
步骤完成后,我们需要将主参数复制回模型参数以进行下一次更新。Apex 中的对应函数是 master_params_to_model_params。
to_model_params
to_model_params (model_pgs:list, master_pgs:list, flat_master:bool=False)
在梯度步骤后,将更新的 fp32 主参数复制到 fp16 模型参数。
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| model_pgs | list | 要复制到的 fp16 模型参数 | |
| master_pgs | list | 要复制的 fp32 主参数 | |
| flat_master | bool | False | master_pgs 之前是否被展平 |
| 返回 | None |
检查溢出
对于动态损失缩放,我们需要知道梯度何时变得无穷大。检查它们的总和比执行 torch.isinf(x).any() 更快。
test_overflow
test_overflow (x:torch.Tensor)
测试 fp16 梯度是否溢出。
x = torch.randn(3,4)
assert not test_overflow(x)
x[1,2] = float('inf')
assert test_overflow(x)然后我们可以在下面的函数中使用它来检查梯度溢出
grad_overflow
grad_overflow (pgs:list)
测试 pgs 中所有 fp16 参数的梯度溢出
copy_clone
copy_clone (d)
ModelToHalf
ModelToHalf (after_create=None, before_fit=None, before_epoch=None, before_train=None, before_batch=None, after_pred=None, after_loss=None, before_backward=None, after_cancel_backward=None, after_backward=None, before_step=None, after_cancel_step=None, after_step=None, after_cancel_batch=None, after_batch=None, after_cancel_train=None, after_train=None, before_validate=None, after_cancel_validate=None, after_validate=None, after_cancel_epoch=None, after_epoch=None, after_cancel_fit=None, after_fit=None)
与 NonNativeMixedPrecision 回调一起使用(但需要在最开始运行)
NonNativeMixedPrecision
NonNativeMixedPrecision (loss_scale:int=512, flat_master:bool=False, dynamic:bool=True, max_loss_scale:float=16777216.0, div_factor:float=2.0, scale_wait:int=500, clip:float=None)
在混合精度下运行训练
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| loss_scale | int | 512 | 非动态损失缩放,用于避免梯度下溢。 |
| flat_master | bool | False | 是否展平 fp32 参数以提高性能 |
| dynamic | bool | True | 是否自动确定损失缩放 |
| max_loss_scale | float | 16777216.0 | 动态损失缩放的起始值 |
| div_factor | float | 2.0 | 溢出时除以此值,在 scale_wait 批次后乘以此值 |
| scale_wait | int | 500 | 等待增加损失缩放的批次数量 |
| clip | float | None | 裁剪梯度的值,max_norm,如 nn.utils.clip_grad_norm_ 中所示 |
Learner.to_non_native_fp16
Learner.to_non_native_fp16 (loss_scale:int=512, flat_master:bool=False, dynamic:bool=True, max_loss_scale:float=16777216.0, div_factor:float=2.0, scale_wait:int=500, clip:float=None)
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| loss_scale | int | 512 | 非动态损失缩放,用于避免梯度下溢。 |
| flat_master | bool | False | 是否展平 fp32 参数以提高性能 |
| dynamic | bool | True | 是否自动确定损失缩放 |
| max_loss_scale | float | 16777216.0 | 动态损失缩放的起始值 |
| div_factor | float | 2.0 | 溢出时除以此值,在 scale_wait 批次后乘以此值 |
| scale_wait | int | 500 | 等待增加损失缩放的批次数量 |
| clip | float | None | 裁剪梯度的值,max_norm,如 nn.utils.clip_grad_norm_ 中所示 |
learn = synth_learner(cuda=True)
learn.model = nn.Sequential(nn.Linear(1,1), nn.Linear(1,1)).cuda()
learn.opt_func = partial(SGD, mom=0.)
learn.splitter = lambda m: [list(m[0].parameters()), list(m[1].parameters())]
learn.to_non_native_fp16()
learn.fit(3, cbs=[TestAfterMixedPrecision(), TestBeforeMixedPrecision()])
#Check the model did train
for v1,v2 in zip(learn.recorder.values[0], learn.recorder.values[-1]): assert v2<v1| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 8.358611 | 10.943352 | 00:00 |
| 1 | 8.330508 | 10.722443 | 00:00 |
| 2 | 8.221409 | 10.485508 | 00:00 |
Learner.to_non_native_fp32
Learner.to_non_native_fp32 ()
learn = learn.to_non_native_fp32()