#! pip install rarfile av
#! pip install -Uq pyopenssl图像序列
如何使用 fastai 训练图像序列到图像序列任务。
本教程使用 fastai 处理图像序列。我们将研究两个任务:
- 首先,我们将在 UCF101 数据集上进行视频分类。你将学习如何将视频转换为单独的帧。我们还将使用 fastai 的中级 API 构建数据处理管道。
- 其次,我们将构建一些简单模型并评估其准确性。
- 最后,我们将训练一个基于 SotA Transformer 的架构。
from fastai.vision.all import *UCF101 行为识别
UCF101 是一个真实行为视频的行为识别数据集,收集自 YouTube,包含 101 个行为类别。该数据集是包含 50 个行为类别的 UCF50 数据集的扩展。
“UCF101 包含 101 个行为类别的 13320 个视频,在行为多样性方面提供了最大范围,并且存在摄像机运动、物体外观和姿态、物体尺度、视角、杂乱背景、光照条件等方面的巨大变化,使其成为迄今为止最具挑战性的数据集。由于大多数可用的行为识别数据集不够真实且由演员表演,UCF101 旨在通过学习和探索新的现实行为类别来鼓励行为识别的进一步研究。”
设置
我们必须从 UCF101 网站下载数据集。这是一个很大的数据集(6.5GB),如果你的连接很慢,你可能想在晚上或终端中进行(以避免阻塞 notebook)。fastai 的 untar_data 无法下载此数据集,因此我们将使用 wget,然后使用 rarfile 解压文件。
fastai 的数据集位于 ~/.fastai/archive 目录中,我们将把 UFC101 下载到那里。
# !wget -P ~/.fastai/archive/ --no-check-certificate https://www.crcv.ucf.edu/data/UCF101/UCF101.rar你可以在终端运行此命令,以避免阻塞 notebook。
让我们创建一个函数来解压下载的数据集。此函数与 untar_data 非常相似,但处理 .rar 文件。
from rarfile import RarFile
def unrar(fname, dest):
"Extract `fname` to `dest` using `rarfile`"
dest = URLs.path(c_key='data')/fname.name.withsuffix('') if dest is None else dest
print(f'extracting to: {dest}')
if not dest.exists():
fname = str(fname)
if fname.endswith('rar'):
with RarFile(fname, 'r') as myrar:
myrar.extractall(dest.parent)
else:
raise Exception(f'Unrecognized archive: {fname}')
rename_extracted(dest)
return dest为了保持一致性,我们将把 UCF 数据集解压到 ~/.fastai/data。这是 fastai 存储解压数据集的地方。
ucf_fname = Path.home()/'.fastai/archive/UCF101.rar'
dest = Path.home()/'.fastai/data/UCF101'解压像这样的大型文件非常慢。
path = unrar(ucf_fname, dest)extracting to: /home/tcapelle/.fastai/data/UCF101数据集解压后的文件结构是每个行为一个文件夹:
path.ls()(#101) [Path('/home/tcapelle/.fastai/data/UCF101/Hammering'),Path('/home/tcapelle/.fastai/data/UCF101/HandstandPushups'),Path('/home/tcapelle/.fastai/data/UCF101/HorseRace'),Path('/home/tcapelle/.fastai/data/UCF101/FrontCrawl'),Path('/home/tcapelle/.fastai/data/UCF101/LongJump'),Path('/home/tcapelle/.fastai/data/UCF101/GolfSwing'),Path('/home/tcapelle/.fastai/data/UCF101/ApplyEyeMakeup'),Path('/home/tcapelle/.fastai/data/UCF101/UnevenBars'),Path('/home/tcapelle/.fastai/data/UCF101/HeadMassage'),Path('/home/tcapelle/.fastai/data/UCF101/Kayaking')...]在里面,你会发现每个实例一个视频,视频是 .avi 格式。我们需要将每个视频转换为图像序列,以便使用 fastai 视觉工具集。
注意
torchvision 有一个内置的视频读取器,可能能够简化此任务。
UCF101-frames
├── ApplyEyeMakeup
| |── v_ApplyEyeMakeup_g01_c01.avi
| ├── v_ApplyEyeMakeup_g01_c02.avi
| | ...
├── Hammering
| ├── v_Hammering_g01_c01.avi
| ├── v_Hammering_g01_c02.avi
| ├── v_Hammering_g01_c03.avi
| | ...
...
├── YoYo
├── v_YoYo_g01_c01.avi
...
├── v_YoYo_g25_c03.avi
我们可以使用 get_files 并传递 '.avi 扩展名一次性获取所有视频。
video_paths = get_files(path, extensions='.avi')
video_paths[0:4](#4) [Path('/home/tcapelle/.fastai/data/UCF101/Hammering/v_Hammering_g22_c05.avi'),Path('/home/tcapelle/.fastai/data/UCF101/Hammering/v_Hammering_g21_c05.avi'),Path('/home/tcapelle/.fastai/data/UCF101/Hammering/v_Hammering_g03_c03.avi'),Path('/home/tcapelle/.fastai/data/UCF101/Hammering/v_Hammering_g18_c02.avi')]我们可以使用 av 将视频转换为帧。
import avdef extract_frames(video_path):
"convert video to PIL images "
video = av.open(str(video_path))
for frame in video.decode(0):
yield frame.to_image()frames = list(extract_frames(video_paths[0]))
frames[0:4][<PIL.Image.Image image mode=RGB size=320x240>,
<PIL.Image.Image image mode=RGB size=320x240>,
<PIL.Image.Image image mode=RGB size=320x240>,
<PIL.Image.Image image mode=RGB size=320x240>]我们有 PIL.Image 对象,因此我们可以直接使用 fastai 的 show_images 方法显示它们。
show_images(frames[0:5])
让我们获取一个视频路径。
video_path = video_paths[0]
video_pathPath('/home/tcapelle/.fastai/data/UCF101/Hammering/v_Hammering_g22_c05.avi')我们想将所有视频导出为帧,让我们构建一个能够将一个视频导出为帧并将结果帧存储在同名文件夹中的函数。
让我们获取文件夹名称。
video_path.relative_to(video_path.parent.parent).with_suffix('')Path('Hammering/v_Hammering_g22_c05')我们还将为 UCF 的帧版本创建一个新目录。你需要至少 7GB 空间来完成此操作,之后你可以删除包含视频的原始 UCF101 文件夹。
path_frames = path.parent/'UCF101-frames'
if not path_frames.exists(): path_frames.mkdir()我们将创建一个函数,该函数接受一个视频路径,并将帧提取到具有相同文件夹结构的新 UCF-frames 数据集中。
def avi2frames(video_path, path_frames=path_frames, force=False):
"Extract frames from avi file to jpgs"
dest_path = path_frames/video_path.relative_to(video_path.parent.parent).with_suffix('')
if not dest_path.exists() or force:
dest_path.mkdir(parents=True, exist_ok=True)
for i, frame in enumerate(extract_frames(video_path)):
frame.save(dest_path/f'{i}.jpg')avi2frames(video_path)
(path_frames/video_path.relative_to(video_path.parent.parent).with_suffix('')).ls()(#161) [Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/63.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/90.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/19.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/111.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/132.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/59.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/46.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/130.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/142.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g22_c05/39.jpg')...]现在我们可以使用 fastcore 的 parallel 批量处理整个数据集。这在 CPU 数量较少的机器上可能会很慢。在 12 核机器上需要 4 分钟。
#parallel(avi2frames, video_paths)之后你会得到一个如下所示的文件夹层级结构:
UCF101-frames
├── ApplyEyeMakeup
| |── v_ApplyEyeMakeup_g01_c01
| │ ├── 0.jpg
| │ ├── 100.jpg
| │ ├── 101.jpg
| | ...
| ├── v_ApplyEyeMakeup_g01_c02
| │ ├── 0.jpg
| │ ├── 100.jpg
| │ ├── 101.jpg
| | ...
├── Hammering
| ├── v_Hammering_g01_c01
| │ ├── 0.jpg
| │ ├── 1.jpg
| │ ├── 2.jpg
| | ...
| ├── v_Hammering_g01_c02
| │ ├── 0.jpg
| │ ├── 1.jpg
| │ ├── 2.jpg
| | ...
| ├── v_Hammering_g01_c03
| │ ├── 0.jpg
| │ ├── 1.jpg
| │ ├── 2.jpg
| | ...
...
├── YoYo
├── v_YoYo_g01_c01
│ ├── 0.jpg
│ ├── 1.jpg
│ ├── 2.jpg
| ...
├── v_YoYo_g25_c03
├── 0.jpg
├── 1.jpg
├── 2.jpg
...
├── 136.jpg
├── 137.jpg
数据管道
我们已经将所有视频转换为图像,现在可以开始构建 fastai 数据管道了。
data_path = Path.home()/'.fastai/data/UCF101-frames'
data_path.ls()[0:3](#3) [Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering'),Path('/home/tcapelle/.fastai/data/UCF101-frames/HandstandPushups'),Path('/home/tcapelle/.fastai/data/UCF101-frames/HorseRace')]每个行为类别有一个文件夹,每个行为实例里面有一个文件夹。
def get_instances(path):
" gets all instances folders paths"
sequence_paths = []
for actions in path.ls():
sequence_paths += actions.ls()
return sequence_paths使用此函数,我们可以获得每个行为的单个实例,**这些就是我们需要分类的图像序列。** 我们将构建一个以实例路径为输入的管道。
instances_path = get_instances(data_path)
instances_path[0:3](#3) [Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g07_c03'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g13_c07')]我们必须按数字顺序对视频帧进行排序。我们将修补 pathlib 的 Path 类,使其返回按数字排序的文件夹中的文件列表。修改 fastcore 的 ls 方法并添加一个可选参数 sort_func 可能是个好主意。
@patch
def ls_sorted(self:Path):
"ls but sorts files by name numerically"
return self.ls().sorted(key=lambda f: int(f.with_suffix('').name))instances_path[0].ls_sorted()(#187) [Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/0.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/1.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/2.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/3.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/4.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/5.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/6.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/7.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/8.jpg'),Path('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02/9.jpg')...]让我们获取前 5 帧。
frames = instances_path[0].ls_sorted()[0:5]
show_images([Image.open(img) for img in frames])
我们将构建一个包含单个帧且可以自我显示的元组。我们将使用与 siamese_tutorial 中相同的想法。由于视频可能有很多帧,并且我们不想全部显示,所以 show 方法将只显示第一帧、中间帧和最后一帧图像。
class ImageTuple(fastuple):
"A tuple of PILImages"
def show(self, ctx=None, **kwargs):
n = len(self)
img0, img1, img2= self[0], self[n//2], self[n-1]
if not isinstance(img1, Tensor):
t0, t1,t2 = tensor(img0), tensor(img1),tensor(img2)
t0, t1,t2 = t0.permute(2,0,1), t1.permute(2,0,1),t2.permute(2,0,1)
else: t0, t1,t2 = img0, img1,img2
return show_image(torch.cat([t0,t1,t2], dim=2), ctx=ctx, **kwargs)ImageTuple(PILImage.create(fn) for fn in frames).show();
我们将使用中级 API 从转换后的列表创建我们的 Dataloader。
class ImageTupleTfm(Transform):
"A wrapper to hold the data on path format"
def __init__(self, seq_len=20):
store_attr()
def encodes(self, path: Path):
"Get a list of images files for folder path"
frames = path.ls_sorted()
n_frames = len(frames)
s = slice(0, min(self.seq_len, n_frames))
return ImageTuple(tuple(PILImage.create(f) for f in frames[s]))tfm = ImageTupleTfm(seq_len=5)
hammering_instance = instances_path[0]
hammering_instancePath('/home/tcapelle/.fastai/data/UCF101-frames/Hammering/v_Hammering_g14_c02')tfm(hammering_instance).show()
通过此设置,我们可以使用 parent_label 作为我们的标签函数。
parent_label(hammering_instance)'Hammering'splits = RandomSplitter()(instances_path)我们将使用 fastai 的 Datasets 类,必须传入一个变换列表。第一个列表 [ImageTupleTfm(5)] 是我们获取 x 的方式,第二个列表 [parent_label, Categorize]] 是我们获取 y 的方式。因此,从每个实例路径中,我们获取前 5 张图像来构建一个 ImageTuple,并使用 parent_label 从父文件夹获取行为标签,然后我们使用 Categorize 对标签进行分类。
ds = Datasets(instances_path, tfms=[[ImageTupleTfm(5)], [parent_label, Categorize]], splits=splits)len(ds)13320dls = ds.dataloaders(bs=4, after_item=[Resize(128), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])重构
def get_action_dataloaders(files, bs=8, image_size=64, seq_len=20, val_idxs=None, **kwargs):
"Create a dataloader with `val_idxs` splits"
splits = RandomSplitter()(files) if val_idxs is None else IndexSplitter(val_idxs)(files)
itfm = ImageTupleTfm(seq_len=seq_len)
ds = Datasets(files, tfms=[[itfm], [parent_label, Categorize]], splits=splits)
dls = ds.dataloaders(bs=bs, after_item=[Resize(image_size), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)], drop_last=True, **kwargs)
return dlsdls = get_action_dataloaders(instances_path, bs=32, image_size=64, seq_len=5)
dls.show_batch()








一个基准模型
我们将构建一个简单的基准模型。它将使用预训练的 resnet 单独编码每一帧。我们利用 TimeDistributed 层将 resnet 同样应用于每一帧。这个简单模型将简单地平均每一帧的概率。还提供了一个 simple_splitter 函数,以避免破坏编码器的预训练权重。
class SimpleModel(Module):
def __init__(self, arch=resnet34, n_out=101):
self.encoder = TimeDistributed(create_body(arch, pretrained=True))
self.head = TimeDistributed(create_head(512, 101))
def forward(self, x):
x = torch.stack(x, dim=1)
return self.head(self.encoder(x)).mean(dim=1)
def simple_splitter(model): return [params(model.encoder), params(model.head)]注意
我们不需要在最后添加 sigmoid 层,因为损失函数会将熵与 sigmoid 融合以获得更好的数值稳定性。我们的模型将为每个类别输出一个值。你可以使用 torch.sigmoid 和 argmax 来恢复预测类别。
model = SimpleModel().cuda()x,y = dls.one_batch()检查模型内部的运行情况和输出始终是个好主意。
print(f'{type(x) = },\n{len(x) = } ,\n{x[0].shape = }, \n{model(x).shape = }')type(x) = <class '__main__.ImageTuple'>,
len(x) = 5 ,
x[0].shape = (32, 3, 64, 64),
model(x).shape = torch.Size([32, 101])我们准备创建一个 Learner。损失函数不是必需的,因为 DataLoader 在构建 Datasets 时对输出使用了 Categorify 变换,因此它已经包含了二元交叉熵。
dls.loss_funcFlattenedLoss of CrossEntropyLoss()我们将利用 MixedPrecision 回调函数来加速训练(通过在 learner 对象上调用 to_fp16)。
注意
TimeDistributed 层非常占用内存(它将图像序列转置到批量维度),所以如果你遇到 OOM(内存不足)错误,尝试减小批量大小。
由于这是一个分类问题,我们将监控分类 accuracy(准确率)。创建 learner 时,你可以直接传递模型分割器。
learn = Learner(dls, model, metrics=[accuracy], splitter=simple_splitter).to_fp16()learn.lr_find()SuggestedLRs(lr_min=0.0006309573538601399, lr_steep=0.00363078061491251)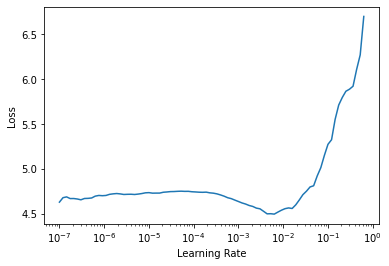
learn.fine_tune(3, 1e-3, freeze_epochs=3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 3.685684 | 3.246746 | 0.295045 | 00:19 |
| 1 | 2.467395 | 2.144252 | 0.477102 | 00:18 |
| 2 | 1.973236 | 1.784474 | 0.545420 | 00:19 |
| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 1.467863 | 1.449896 | 0.626877 | 00:24 |
| 1 | 1.143187 | 1.200496 | 0.679805 | 00:24 |
| 2 | 0.941360 | 1.152383 | 0.696321 | 00:24 |
对于只有 5 帧的简单基准模型来说,68% 的准确率还不错。
learn.show_results()








我们可以通过将图像编码器的输出传递给 nn.LSTM 来改善模型,以获取帧间的关联。为此,我们必须获取图像编码器的特征,因此需要修改代码,使用 create_body 函数并在之后添加一个池化层。
arch = resnet34
encoder = nn.Sequential(create_body(arch, pretrained=True), nn.AdaptiveAvgPool2d(1), Flatten()).cuda()如果我们检查编码器的输出,对于每张图像,我们得到一个 512 维的特征图。
encoder(x[0]).shape(32, 512)tencoder = TimeDistributed(encoder)
tencoder(torch.stack(x, dim=1)).shape(32, 5, 512)这非常适合作为循环层的输入。让我们重构代码并在最后添加一个线性层。我们将把隐藏状态输出到一个线性层来计算概率。其背后的思想是,隐藏状态编码了序列的时间信息。
class RNNModel(Module):
def __init__(self, arch=resnet34, n_out=101, num_rnn_layers=1):
self.encoder = TimeDistributed(nn.Sequential(create_body(arch, pretrained=True), nn.AdaptiveAvgPool2d(1), Flatten()))
self.rnn = nn.LSTM(512, 512, num_layers=num_rnn_layers, batch_first=True)
self.head = LinBnDrop(num_rnn_layers*512, n_out)
def forward(self, x):
x = torch.stack(x, dim=1)
x = self.encoder(x)
bs = x.shape[0]
_, (h, _) = self.rnn(x)
return self.head(h.view(bs,-1))让我们创建一个分割函数来单独训练编码器和其余部分。
def rnnmodel_splitter(model):
return [params(model.encoder), params(model.rnn)+params(model.head)]model2 = RNNModel().cuda()learn = Learner(dls, model2, metrics=[accuracy], splitter=rnnmodel_splitter).to_fp16()learn.lr_find()SuggestedLRs(lr_min=0.0006309573538601399, lr_steep=0.0012022644514217973)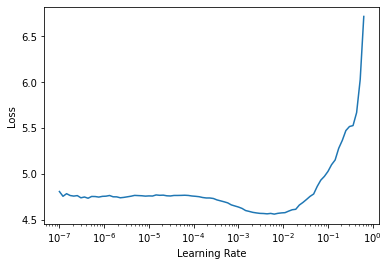
learn.fine_tune(5, 5e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 3.081921 | 2.968944 | 0.295796 | 00:19 |
| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 1.965607 | 1.890396 | 0.516892 | 00:25 |
| 1 | 1.544786 | 1.648921 | 0.608108 | 00:24 |
| 2 | 1.007738 | 1.157811 | 0.702703 | 00:25 |
| 3 | 0.537038 | 0.885042 | 0.771772 | 00:24 |
| 4 | 0.351384 | 0.849636 | 0.781156 | 00:25 |
这个模型更难训练。一个好主意是添加一些 Dropout。让我们尝试增加序列长度。另一种方法是对此类任务使用更好的层,例如 ConvLSTM 或能够以更复杂方式建模时空关系的图像 Transformer。一些想法:
- 尝试以不同方式采样帧(随机间隔、更多帧等)。
基于 Transformer 的模型
新的基于 Transformer 的架构快速浏览
最近在引入 Visual Transformer (ViT) 后,出现了一系列基于 Transformer 的图像模型。我们目前有这种架构的许多变体,并在 pytorch 中与 timm nicely 集成,@lucidrains 维护着一个包含所有变体和优雅的 pytorch 实现的仓库。
最近,图像模型已扩展到视频/图像序列,它们使用 Transformer 共同编码空间和时间信息。在这里,我们将在行为识别任务上训练 TimeSformer 架构,因为它似乎更容易从头开始训练。我们将使用 @lucidrains 的实现。
目前我们无法访问预训练模型,但在某些块上加载 ViT 权重是可能的,但这里没有这样做。
安装
首先,我们需要安装模型。
!pip install -Uq timesformer-pytorchfrom timesformer_pytorch import TimeSformer训练
TimeSformer 实现期望图像序列的格式为:(batch_size, seq_len, c, w, h)。我们需要封装模型,以便在执行前向方法之前堆叠图像序列。
class MyTimeSformer(TimeSformer):
def forward(self, x):
x = torch.stack(x, dim=1)
return super().forward(x)timesformer = MyTimeSformer(
dim = 128,
image_size = 128,
patch_size = 16,
num_frames = 5,
num_classes = 101,
depth = 12,
heads = 8,
dim_head = 64,
attn_dropout = 0.1,
ff_dropout = 0.1
).cuda()learn_tf = Learner(dls, timesformer, metrics=[accuracy]).to_fp16()learn_tf.lr_find()SuggestedLRs(lr_min=0.025118863582611083, lr_steep=0.2089296132326126)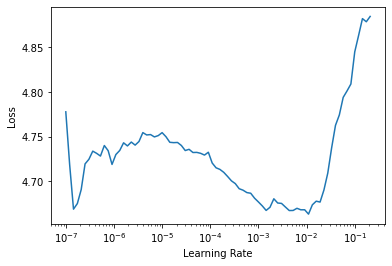
learn_tf.fit_one_cycle(12, 5e-4)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 4.227850 | 4.114154 | 0.091216 | 00:41 |
| 1 | 3.735752 | 3.694664 | 0.141517 | 00:42 |
| 2 | 3.160729 | 3.085824 | 0.256381 | 00:41 |
| 3 | 2.540461 | 2.478563 | 0.380255 | 00:42 |
| 4 | 1.878038 | 1.880847 | 0.536411 | 00:42 |
| 5 | 1.213030 | 1.442322 | 0.642643 | 00:42 |
| 6 | 0.744001 | 1.153427 | 0.720345 | 00:42 |
| 7 | 0.421604 | 1.041846 | 0.746997 | 00:42 |
| 8 | 0.203065 | 0.959380 | 0.779655 | 00:42 |
| 9 | 0.112700 | 0.902984 | 0.792042 | 00:42 |
| 10 | 0.058495 | 0.871788 | 0.801802 | 00:42 |
| 11 | 0.043413 | 0.868007 | 0.805931 | 00:42 |
learn_tf.show_results()







