from fastai.data.external import untar_data,URLs
from fastai.data.transforms import get_image_files定制新任务 - Siamese
如何使用中层 API 进行数据收集、模型创建和训练
在本教程中,我们将学习如何使用 fastai 库的中层 API 处理一种新类型的任务。我们将使用的示例是 Siamese 网络,它接收两张图像并判断它们是否属于同一类别。我们将特别看到:
- 如何从标准的 PyTorch
Datasets快速获取 fastai 的DataLoaders - 如何将其适配到
Transform中,以利用 fastai 的部分 show 功能 - 如何为自定义任务增加
show_batch/show_results的新行为 - 如何编写自定义的
DataBlock - 如何从预训练模型创建自己的模型
- 如何向
Learner传递自定义的splitter以利用迁移学习
准备数据
为了使我们的数据准备好用于训练模型,我们需要在 fastai 中创建一个 DataLoaders 对象。它仅仅是训练 DataLoader 和验证 DataLoader 的一个包装器,所以如果你已经有了自己的 PyTorch dataloaders,你可以直接创建这样的对象。
在这里,我们还没有任何现成的东西。通常,在使用 PyTorch 时,第一步是创建一个 Dataset,然后将其包装在 DataLoader 中。我们将先这样做,然后看看如何将这个 Dataset 更改为 Transform,从而利用 fastai 的功能来显示批次或在 GPU 上使用数据增强。最后,我们将看到如何定制 data block API 并创建我们自己的新 TransformBlock。
纯 PyTorch 实现
首先,我们将仅使用 PyTorch 和 PIL 来创建 Dataset,并看看如何将其导入 fastai。我们将使用的 fastai 辅助函数只有 untar_data(用于下载和解压数据集)和 get_image_files(用于递归查找文件夹中的所有图像)。在这里,我们将使用 牛津-IIIT 宠物数据集。
untar_data 返回一个 pathlib.Path 对象,其中包含解压后的数据集的位置,在本例中,所有图像都在一个 images 子文件夹中。
path = untar_data(URLs.PETS)
files = get_image_files(path/"images")
files[0]Path('/home/jhoward/.fastai/data/oxford-iiit-pet/images/great_pyrenees_173.jpg')我们可以用 PIL 打开第一张图片看看
import PILimg = PIL.Image.open(files[0])
img
我们将所有标准预处理(缩放大小、转换为 tensor、除以 255 和通道重新排序)包装到一个辅助函数中
import torch
import numpy as npdef open_image(fname, size=224):
img = PIL.Image.open(fname).convert('RGB')
img = img.resize((size, size))
t = torch.Tensor(np.array(img))
return t.permute(2,0,1).float()/255.0open_image(files[0]).shapetorch.Size([3, 224, 224])我们可以看到图像的标签在文件名中,位于最后一个 _ 和一些数字之前。然后我们可以使用正则表达式创建一个标签函数。
import redef label_func(fname):
return re.match(r'^(.*)_\d+.jpg$', fname.name).groups()[0]
label_func(files[0])'great_pyrenees'现在收集所有唯一的标签
labels = list(set(files.map(label_func)))
len(labels)37因此我们有 37 种不同的宠物品种。为了创建 Siamese 数据集,我们需要创建图像元组作为输入,目标将是 True 如果图像属于同一类别,否则为 False。有一个从类别到该类别文件名列表的映射将非常有用,以便快速为任何类别随机选取一张图像。
lbl2files = {l: [f for f in files if label_func(f) == l] for l in labels}现在我们准备好创建数据集了。对于训练集,我们将遍历所有训练文件名作为第一张图像,然后随机选取:
- 与第一张图像属于同一类别的文件名作为第二张图像(概率为 0.5)
- 与第一张图像属于不同类别的文件名作为第二张图像(概率为 0.5)
每次访问项目时都会进行这种随机抽取,以便获得尽可能多的样本。然而,对于验证集,我们将一次性固定这种随机抽取(否则我们在每个 epoch 都会在不同的数据集上进行验证)。
import randomclass SiameseDataset(torch.utils.data.Dataset):
def __init__(self, files, is_valid=False):
self.files,self.is_valid = files,is_valid
if is_valid: self.files2 = [self._draw(f) for f in files]
def __getitem__(self, i):
file1 = self.files[i]
(file2,same) = self.files2[i] if self.is_valid else self._draw(file1)
img1,img2 = open_image(file1),open_image(file2)
return (img1, img2, torch.Tensor([same]).squeeze())
def __len__(self): return len(self.files)
def _draw(self, f):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice([l for l in labels if l != cls])
return random.choice(lbl2files[cls]),same我们只需将文件名分割为训练集和验证集即可使用它。
idxs = np.random.permutation(range(len(files)))
cut = int(0.8 * len(files))
train_files = files[idxs[:cut]]
valid_files = files[idxs[cut:]]然后我们可以用它来创建数据集。
train_ds = SiameseDataset(train_files)
valid_ds = SiameseDataset(valid_files, is_valid=True)以上所有内容对于你的自定义问题都会有所不同,关键是,一旦你有了 Datasets,就可以使用以下工厂方法创建一个 fastai 的 DataLoaders:
from fastai.data.core import DataLoadersdls = DataLoaders.from_dsets(train_ds, valid_ds)然后你就可以在 Learner 中使用这个 DataLoaders 对象并开始训练了。大多数不依赖于显示的方法(例如 DataLoaders.show_batch 和 Learner.show_results 除外)都应该能正常工作。例如,你可以使用以下方法获取和检查一个批次:
b = dls.one_batch()如果你想使用 GPU,只需写
dls = dls.cuda()现在有点令人烦恼的是,如果我们想归一化图像或应用数据增强,就必须重写 fastai 中已有的所有内容。通过对我们编写的代码进行少量更改,我们仍然可以访问所有这些功能,并且 show 方法也能正常工作,锦上添花。让我们看看如何实现。
使用中层 API
当你有像之前那样的自定义数据集时,只需将 __getitem__ 函数更改为 encodes,就可以轻松将其转换为 fastai Transform。通常,fastai 中的 Transform 在应用于项目时会调用 encodes 方法(有点像 PyTorch modules 在应用于对象时调用 forward),因此这将你的 python 数据集转换为一个将整数转换为数据的函数。
如果你然后返回一个元组(或元组的子类),并使用 fastai 的语义类型,那么你就可以对数据应用任何其他 fastai 的 transform,并且它会被正确分发。让我们看看它是如何工作的
from fastai.vision.all import *class SiameseTransform(Transform):
def __init__(self, files, is_valid=False):
self.files,self.is_valid = files,is_valid
if is_valid: self.files2 = [self._draw(f) for f in files]
def encodes(self, i):
file1 = self.files[i]
(file2,same) = self.files2[i] if self.is_valid else self._draw(file1)
img1,img2 = open_image(file1),open_image(file2)
return (TensorImage(img1), TensorImage(img2), torch.Tensor([same]).squeeze())
def _draw(self, f):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice([l for l in labels if l != cls])
return random.choice(lbl2files[cls]),same所以有三件事发生了变化:
__len__消失了,我们不需要它__getitem___变成了encodes- 我们为图像返回
TensorImage
如何用它来构建数据集呢?我们将使用 TfmdLists。它只是一个对象,对列表懒惰地应用 transforms 的集合。在这里,由于我们的 transform 接受整数,我们将为这个列表传递简单的范围。
train_tl= TfmdLists(range(len(train_files)), SiameseTransform(train_files))
valid_tl= TfmdLists(range(len(valid_files)), SiameseTransform(valid_files, is_valid=True))然后,当我们创建一个 DataLoader 时,我们可以添加任何我们喜欢的 transform。fastai 用它自己的版本替换了 PyTorch DataLoader,该版本具有更多的钩子(但与 PyTorch 完全兼容)。我们希望应用于项目的 transforms 应该传递给 after_item,我们希望应用于数据批次的 transforms 应该传递给 after_batch。
dls = DataLoaders.from_dsets(train_tl, valid_tl,
after_batch=[Normalize.from_stats(*imagenet_stats), *aug_transforms()])
dls = dls.cuda()所以只需做一点改动,我们就可以使用 fastai 的归一化和数据增强功能。如果我们愿意多做一些额外的编码工作,甚至可以让 show 方法正确地工作。
使 show 方法工作
fastai 中的 show 方法都依赖于某些类型能够自行显示。此外,一些为了显示目的需要反转的 transforms(比如将类别更改为索引,或进行归一化)有一个 decodes 方法来撤销它们的 encodes 所做的事情。通常,fastai 会调用这些 decodes 方法,直到遇到一个知道如何自行显示的类型,然后调用该类型的 show 方法。
为了让它工作,我们首先创建一个带有 show 方法的新类型!
class SiameseImage(fastuple):
def show(self, ctx=None, **kwargs):
if len(self) > 2:
img1,img2,similarity = self
else:
img1,img2 = self
similarity = 'Undetermined'
if not isinstance(img1, Tensor):
if img2.size != img1.size: img2 = img2.resize(img1.size)
t1,t2 = tensor(img1),tensor(img2)
t1,t2 = t1.permute(2,0,1),t2.permute(2,0,1)
else: t1,t2 = img1,img2
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2), title=similarity, ctx=ctx, **kwargs)测试的第一部分有一些你可以忽略的代码,它主要是为了让 show 方法同时适用于 PIL Image 和 tensors。主要内容发生在最后两行:我们创建一条 10 像素的黑线,并显示将两张图像串联起来的 tensor,中间有黑线。通常,ctx 代表我们将显示对象的地方。在这种情况下,它可以是一个给定的 matplotlib 轴。
让我们看一个例子
img = PILImage.create(files[0])
img1 = PILImage.create(files[1])
s = SiameseImage(img, img1, False)
s.show();
注意,我们使用了 fastai 类型 PILImage 而不是 PIL.Image。这是为了访问 fastai 的 transforms。例如,我们可以直接在 SiamesImage 上使用 Resize 和 ToTensor。由于它继承自 tuple,这些 transforms 会被分派并应用于有意义的部分(PILImages,而不是 bool)。
tst = Resize(224)(s)
tst = ToTensor()(tst)
tst.show();
现在让我们稍微重写一下之前的 transform。例如,它可以直接接受文件而不是整数。另外,在 fastai 中,分割通常由辅助函数处理,这些函数返回两个整数列表(训练集和验证集中的整数),所以让我们稍微调整一下之前的代码,使验证图像一次性抽取。我们还需要为训练和验证分割单独添加从类别到文件名列表的映射字典,以便训练集和验证集之间完全分离,即“训练”文件只能从训练分割中抽取样本;“验证”文件只能从验证分割中抽取样本。
class SiameseTransform(Transform):
def __init__(self, files, splits):
self.splbl2files = [{l: [f for f in files[splits[i]] if label_func(f) == l] for l in labels}
for i in range(2)]
self.valid = {f: self._draw(f,1) for f in files[splits[1]]}
def encodes(self, f):
f2,same = self.valid.get(f, self._draw(f,0))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, same)
def _draw(self, f, split=0):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(self.splbl2files[split][cls]),same然后我们使用 RandomSplitter 创建分割
splits = RandomSplitter()(files)
tfm = SiameseTransform(files, splits)我们测试 tfm.valid 不包含训练分割中的项
valids = [v[0] for k,v in tfm.valid.items()]
assert not [v for v in valids if v in files[splits[0]]]然后我们可以将这些分割传递给 TfmdLists,它将为我们创建验证集和训练集。
tls = TfmdLists(files, tfm, splits=splits)我们现在可以使用像 show_at 这样的方法了
show_at(tls.valid, 0)
我们可以像之前一样创建一个 DataLoaders,方法是为 after_item 和 after_batch 添加自定义 transforms。
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])如果我们现在尝试使用 show_batch,它将无法完全正常工作:默认行为依赖于使用数据块构建的数据,而我们使用了一个大的 transform 来处理所有内容。因此,我们没有输入是某种类型、输出是某种类型,而是整个数据只有一种大类型。如果我们查看一个批次,可以看到 fastai 库已经为我们通过所有 transform 和批处理操作传播了该类型。
b = dls.one_batch()
type(b)__main__.SiameseImage当我们调用 show_batch 时,fastai 库会发现整个批次都有 show 方法,因此它应该知道如何自行显示。它将直接把整个批次发送到按类型分派的函数 show_batch。这个函数的签名如下:
show_batch(x, y, samples, ctxs=None, **kwargs)其中 kwargs 是特定于应用的(例如,在这里我们将有 nrows、ncols 和 figsize)。在我们的例子中,整个批次将作为 x 发送,y 和 samples 将为 None(这些参数用于当批次没有知道如何自行显示的类型时,请参见下一节)。
要编写自定义的 show_batch,我们只需要像这样在 x 上使用类型注释:
@dispatch
def show_batch(x:SiameseImage, y, samples, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(x[0].shape[0], max_n), nrows=None, ncols=ncols, figsize=figsize)
for i,ctx in enumerate(ctxs): SiameseImage(x[0][i], x[1][i], ['Not similar','Similar'][x[2][i].item()]).show(ctx=ctx)我们将在下一节看到,当批次没有 show 方法时(大多数情况下是这样,只有批次的输入和目标有 show 方法),行为是不同的。在这种情况下,参数 y 和 samples 就很有用。在这里,所有东西都在 x 中,因为整个批次知道如何自行显示,所以它作为一个整体发送。
在这里,我们使用实用函数 get_grid 创建一个 matplotlib 轴列表,然后将其传递给所有 SiameseImage.show。让我们看看实际效果如何
b = dls.one_batch()dls._types{__main__.SiameseImage: [fastai.torch_core.TensorImage,
fastai.torch_core.TensorImage,
torch.Tensor]}dls.show_batch()
我们将在训练部分看到,自定义 show_results 同样简单。现在让我们看看如何编写自己的 data block。
编写自定义 data block
Siamese 问题只是输入是图像元组、目标是类别的问题的一个特例。如果“图像元组”这种类型在其他具有不同目标的问题中再次出现,那么为它创建一个自定义 block 可能会很有用,以便能够利用 data block API 的强大功能。
注意: 如果你的问题只有一种特定的设置,并且不需要针对各种目标的模块化方面,那么我们之前所做的工作就完全没问题,你不需要再深入研究。
让我们创建一个类型来表示我们的两张图像元组
class ImageTuple(fastuple):
@classmethod
def create(cls, fns): return cls(tuple(PILImage.create(f) for f in fns))
def show(self, ctx=None, **kwargs):
t1,t2 = self
if not isinstance(t1, Tensor) or not isinstance(t2, Tensor) or t1.shape != t2.shape: return ctx
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2), ctx=ctx, **kwargs)由于它是 fastuple 的子类,Transform 将应用于元组的每一部分。例如,ToTensor 会将这个 ImageTuple 转换为一个 TensorImage 元组。
img = ImageTuple.create((files[0], files[1]))
tst = ToTensor()(img)
type(tst[0]),type(tst[1])(fastai.torch_core.TensorImage, fastai.torch_core.TensorImage)在 show 方法中,我们这次没有处理非 tensor 元素(我们可以复制粘贴之前的代码)。显示假定我们在处理管道中有 resize transform,并且将图像转换为 tensors
img1 = Resize(224)(img)
tst = ToTensor()(img1)
tst.show();
我们现在可以定义与 ImageTuple 关联的 block,并将其用于 data block API。一个 block 本质上是一组默认的 transforms,在这里我们指定如何创建 ImageTuple 以及图像预处理所需的 IntToFloatTensor transform
def ImageTupleBlock(): return TransformBlock(type_tfms=ImageTuple.create, batch_tfms=IntToFloatTensor)要使用 data block API 收集数据,我们将使用以下函数
splits_files = [files[splits[i]] for i in range(2)]
splits_sets = mapped(set, splits_files)def get_split(f):
for i,s in enumerate(splits_sets):
if f in s: return i
raise ValueError(f'File {f} is not presented in any split.')splbl2files = [{l: [f for f in s if label_func(f) == l] for l in labels} for s in splits_sets]def splitter(items):
def get_split_files(i): return [j for j,(f1,f2,same) in enumerate(items) if get_split(f1)==i]
return get_split_files(0),get_split_files(1)def draw_other(f):
same = random.random() < 0.5
cls = label_func(f)
split = get_split(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(splbl2files[split][cls]),samedef get_tuples(files): return [[f, *draw_other(f)] for f in files]然后我们就可以定义我们的 block 了
def get_x(t): return t[:2]
def get_y(t): return t[2]siamese = DataBlock(
blocks=(ImageTupleBlock, CategoryBlock),
get_items=get_tuples,
get_x=get_x, get_y=get_y,
splitter=splitter,
item_tfms=Resize(224),
batch_tfms=[Normalize.from_stats(*imagenet_stats)]
)dls = siamese.dataloaders(files)我们可以使用 explode_types 方法检查一个批次中元素的类型。在这里,我们有一个元组,其中包含一个由两个 TensorImage 组成的 ImageTuple 和一个 TensorCategory。即使将样本 collate 到一起后,transform 也正确地保留了所有内容的类型!
b = dls.one_batch()
explode_types(b){tuple: [{__main__.ImageTuple: [fastai.torch_core.TensorImage,
fastai.torch_core.TensorImage]},
fastai.torch_core.TensorCategory]}这里的 show_batch 方法可以直接工作。但是整个批次只是一个元组,因此没有 show 方法。要自定义事物的组织方式,我们可以扩展一个分派的 show_batch 函数。
@dispatch
def show_batch(x:ImageTuple, y, samples, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(len(samples), max_n), nrows=nrows, ncols=ncols, figsize=figsize)
ctxs = get_show_batch_func(object)(x, y, samples, ctxs=ctxs, max_n=max_n, **kwargs)
return ctxs顺带一提,x 和 y 实际上并未使用(所有需要显示的内容都在 samples 列表中)。它们只是为了类型分派而被传递,因为它们携带着我们输入和目标的类型。
我们现在可以看一看
dls.show_batch()
训练模型
模型
我们现在可以训练模型了。我们将使用一个非常简单的方法:取一个预训练模型的 body,让两张图片通过它。然后以通常的方式构建 head,只是特征数增加一倍。模型本身可以这样写:
class SiameseModel(Module):
def __init__(self, encoder, head):
self.encoder,self.head = encoder,head
def forward(self, x1, x2):
ftrs = torch.cat([self.encoder(x1), self.encoder(x2)], dim=1)
return self.head(ftrs)对于我们的编码器,我们使用 fastai 函数 create_body。它接收一个架构和一个切割索引。默认情况下,它将使用我们选择的模型的预训练版本。如果我们想检查 fastai 通常在何处切割模型,可以查看 model_meta 字典:
model_meta[resnet34]{'cut': -2,
'split': <function fastai.vision.learner._resnet_split(m)>,
'stats': ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])}所以我们需要在 -2 处切割
encoder = create_body(resnet34(), cut=-2)让我们看看这个编码器的最后一个 block
encoder[-1]Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)它最终有 512 个特征,所以对于我们的自定义 head,我们需要将其乘以 4(即 2*2):乘以 2 是因为我们串联了两张图片,再乘以 2 是因为 fastai 的 concat-pool 技巧(我们串联了特征的平均池化和最大池化)。create_head 函数将为我们提供 fastai 迁移学习模型中通常使用的 head。
我们还需要定义 head 的输出数量 n_out,在本例中为 2:一个用于预测两张图片来自同一类别,另一个用于预测相反情况。
head = create_head(512*2, 2, ps=0.5)
model = SiameseModel(encoder, head)让我们看看生成的 head
headSequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten(full=False)
(2): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=2048, out_features=512, bias=False)
(5): ReLU(inplace=True)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=512, out_features=2, bias=False)
)训练模型
我们几乎准备好训练我们的模型了。最后缺少的一块是一个自定义 splitter:为了高效地使用迁移学习,我们首先想要冻结预训练模型,只训练 head。splitter 是一个函数,它接收一个模型并返回参数列表。params 函数对于返回模型的所有参数很有用,因此我们可以像这样创建一个简单的 splitter:
def siamese_splitter(model):
return [params(model.encoder), params(model.head)]然后我们使用 fastai 传统的 CrossEntropyLossFlat 损失函数(与 nn.CrossEntropyLoss 相同,但进行了展平)。唯一的问题是,如果使用中层 API 构建的数据,我们的目标是布尔 tensor,所以我们需要将其转换为整数,否则 PyTorch 会抛出错误。
def loss_func(out, targ):
return CrossEntropyLossFlat()(out, targ.long())让我们获取由中层 API 构建的数据
class SiameseTransform(Transform):
def __init__(self, files, splits):
self.splbl2files = [{l: [f for f in files[splits[i]] if label_func(f) == l] for l in labels}
for i in range(2)]
self.valid = {f: self._draw(f,1) for f in files[splits[1]]}
def encodes(self, f):
f2,same = self.valid.get(f, self._draw(f,0))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, int(same))
def _draw(self, f, split=0):
same = random.random() < 0.5
cls = label_func(f)
if not same: cls = random.choice(L(l for l in labels if l != cls))
return random.choice(self.splbl2files[split][cls]),samesplits = RandomSplitter()(files)
tfm = SiameseTransform(files, splits)
tls = TfmdLists(files, tfm, splits=splits)
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])再次测试 tfm.valid 不包含训练分割中的项
valids = [v[0] for k,v in tfm.valid.items()]
assert not [v for v in valids if v in files[splits[0]]]然后我们可以创建我们的 Learner
learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), splitter=siamese_splitter, metrics=accuracy)由于我们没有使用直接为我们创建 Learner 的便捷函数,我们需要手动 freeze 它
learn.freeze()然后我们可以使用学习率查找器
learn.lr_find()SuggestedLRs(lr_min=0.0019054606556892395, lr_steep=1.737800812406931e-05)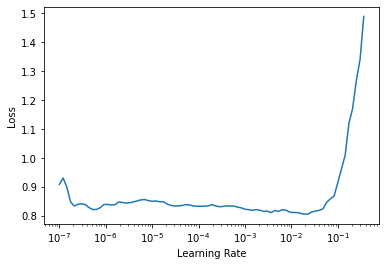
训练 head 一段时间
learn.fit_one_cycle(4, 3e-3)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.543907 | 0.378830 | 0.836942 | 00:30 |
| 1 | 0.389485 | 0.263416 | 0.889716 | 00:35 |
| 2 | 0.289101 | 0.199503 | 0.920162 | 00:27 |
| 3 | 0.244186 | 0.176951 | 0.932341 | 00:40 |
解除冻结并训练整个模型一段时间
learn.unfreeze()learn.fit_one_cycle(4, slice(1e-6,1e-4))| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.235934 | 0.175252 | 0.933694 | 00:53 |
| 1 | 0.218259 | 0.164884 | 0.933018 | 00:36 |
| 2 | 0.228709 | 0.164789 | 0.933694 | 00:58 |
| 3 | 0.203605 | 0.160317 | 0.935724 | 00:58 |
使 show_results 方法工作
@dispatch
def show_results(x:SiameseImage, y, samples, outs, ctxs=None, max_n=6, nrows=None, ncols=2, figsize=None, **kwargs):
if figsize is None: figsize = (ncols*6, max_n//ncols * 3)
if ctxs is None: ctxs = get_grid(min(x[0].shape[0], max_n), nrows=None, ncols=ncols, figsize=figsize)
for i,ctx in enumerate(ctxs):
title = f'Actual: {["Not similar","Similar"][x[2][i].item()]} \n Prediction: {["Not similar","Similar"][y[2][i].item()]}'
SiameseImage(x[0][i], x[1][i], title).show(ctx=ctx)learn.show_results()
为 Learner 添加 siampredict 方法,以自动显示图像和预测
@patch
def siampredict(self:Learner, item, rm_type_tfms=None, with_input=False):
res = self.predict(item, rm_type_tfms=None, with_input=False)
if res[0] == tensor(0):
SiameseImage(item[0], item[1], 'Prediction: Not similar').show()
else:
SiameseImage(item[0], item[1], 'Prediction: Similar').show()
return resimgtest = PILImage.create(files[0])
imgval = PILImage.create(files[100])
siamtest = SiameseImage(imgval, imgtest)
siamtest.show();
res = learn.siampredict(siamtest)