lbls = np.random.randint(0, 2, size=(10)) # Dataset of size 10 (train=8, valid=2)
is_valid = lambda i: i >= 8
dblock = DataBlock(blocks=[CategoryBlock],
getters=[lambda i: lbls[i]], splitter=FuncSplitter(is_valid))
dset = dblock.datasets(list(range(10)))
item_tfms = [ToTensor()]
wgts = range(8) # len(wgts) == 8
dls = dset.weighted_dataloaders(bs=1, wgts=wgts, after_item=item_tfms)数据回调
处理学习器数据的数据回调
CollectDataCallback
CollectDataCallback (after_create=None, before_fit=None, before_epoch=None, before_train=None, before_batch=None, after_pred=None, after_loss=None, before_backward=None, after_cancel_backward=None, after_backward=None, before_step=None, after_cancel_step=None, after_step=None, after_cancel_batch=None, after_batch=None, after_cancel_train=None, after_train=None, before_validate=None, after_cancel_validate=None, after_validate=None, after_cancel_epoch=None, after_epoch=None, after_cancel_fit=None, after_fit=None)
收集所有批次,以及 pred 和 loss,存入 self.data。主要用于测试
WeightedDL
WeightedDL (dataset=None, bs=None, wgts=None, shuffle:bool=False, num_workers:int=None, verbose:bool=False, do_setup:bool=True, pin_memory=False, timeout=0, batch_size=None, drop_last=False, indexed=None, n=None, device=None, persistent_workers=False, pin_memory_device='', wif=None, before_iter=None, after_item=None, before_batch=None, after_batch=None, after_iter=None, create_batches=None, create_item=None, create_batch=None, retain=None, get_idxs=None, sample=None, shuffle_fn=None, do_batch=None)
加权数据加载器,其中 wgts 仅用于训练集
Datasets.weighted_dataloaders
Datasets.weighted_dataloaders (wgts, bs=64, shuffle_train:bool=None, shuffle:bool=True, val_shuffle:bool=False, n:int=None, path:str|Path='.', dl_type:TfmdDL=None, dl_kwargs:list=None, device:torch.device=None, drop_last:bool=None, val_bs:int=None)
为训练集创建使用 wgts 的加权数据加载器 WeightedDL
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| wgts | |||
| bs | int | 64 | 批量大小 |
| shuffle_train | bool | None | (已弃用,请使用 shuffle) 打乱训练集 DataLoader |
| shuffle | bool | True | 打乱训练集 DataLoader |
| val_shuffle | bool | False | 打乱验证集 DataLoader |
| n | int | None | 用于创建 DataLoader 的 Datasets 大小 |
| path | str | pathlib.Path | . | DataLoaders 中使用的路径 |
| dl_type | TfmdDL | None | DataLoader 类型 |
| dl_kwargs | list | None | 传递给各个 DataLoader 的 kwargs 列表 |
| device | device | None | 放置 DataLoaders 的设备 |
| drop_last | bool | None | 丢弃最后一个不完整的批次,默认为 shuffle 的值 |
| val_bs | int | None | 验证集批量大小,默认为 bs 的值 |
dls.show_batch() # if len(wgts) != 8, this will fail"1n = 160
dsets = Datasets(torch.arange(n).float())
dls = dsets.weighted_dataloaders(wgts=range(n), bs=16)
learn = synth_learner(data=dls, cbs=CollectDataCallback)learn.fit(1)
t = concat(*learn.collect_data.data.itemgot(0,0))
plt.hist(t.numpy());[0, nan, None, '00:00']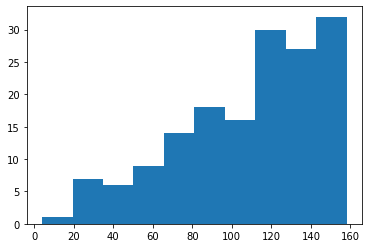
DataBlock.weighted_dataloaders
DataBlock.weighted_dataloaders (source, wgts, bs=64, verbose:bool=False, shuffle_train:bool=None, shuffle:bool=True, val_shuffle:bool=False, n:int=None, path:str|Path='.', dl_type:TfmdDL=None, dl_kwargs:list=None, device:torch.device=None, drop_last:bool=None, val_bs:int=None)
为数据集创建使用 wgts 的加权数据加载器 WeightedDL
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| 源 | |||
| wgts | |||
| bs | int | 64 | 批量大小 |
| verbose | bool | False | |
| shuffle_train | bool | None | (已弃用,请使用 shuffle) 打乱训练集 DataLoader |
| shuffle | bool | True | 打乱训练集 DataLoader |
| val_shuffle | bool | False | 打乱验证集 DataLoader |
| n | int | None | 用于创建 DataLoader 的 Datasets 大小 |
| path | str | pathlib.Path | . | DataLoaders 中使用的路径 |
| dl_type | TfmdDL | None | DataLoader 类型 |
| dl_kwargs | list | None | 传递给各个 DataLoader 的 kwargs 列表 |
| device | device | None | 放置 DataLoaders 的设备 |
| drop_last | bool | None | 丢弃最后一个不完整的批次,默认为 shuffle 的值 |
| val_bs | int | None | 验证集批量大小,默认为 bs 的值 |
dls = dblock.weighted_dataloaders(list(range(10)), wgts, bs=1)
dls.show_batch()0PartialDL
PartialDL (dataset=None, bs=None, partial_n=None, shuffle:bool=False, num_workers:int=None, verbose:bool=False, do_setup:bool=True, pin_memory=False, timeout=0, batch_size=None, drop_last=False, indexed=None, n=None, device=None, persistent_workers=False, pin_memory_device='', wif=None, before_iter=None, after_item=None, before_batch=None, after_batch=None, after_iter=None, create_batches=None, create_item=None, create_batch=None, retain=None, get_idxs=None, sample=None, shuffle_fn=None, do_batch=None)
每个周期随机选择部分数据量
FilteredBase.partial_dataloaders
FilteredBase.partial_dataloaders (partial_n, bs=64, shuffle_train:bool=None, shuffle:bool=True, val_shuffle:bool=False, n:int=None, path:str|Path='.', dl_type:TfmdDL=None, dl_kwargs:list=None, device:torch.device=None, drop_last:bool=None, val_bs:int=None)
为训练集创建部分数据加载器 PartialDL
| 类型 | 默认值 | 详情 | |
|---|---|---|---|
| partial_n | |||
| bs | int | 64 | 批量大小 |
| shuffle_train | bool | None | (已弃用,请使用 shuffle) 打乱训练集 DataLoader |
| shuffle | bool | True | 打乱训练集 DataLoader |
| val_shuffle | bool | False | 打乱验证集 DataLoader |
| n | int | None | 用于创建 DataLoader 的 Datasets 大小 |
| path | str | pathlib.Path | . | DataLoaders 中使用的路径 |
| dl_type | TfmdDL | None | DataLoader 类型 |
| dl_kwargs | list | None | 传递给各个 DataLoader 的 kwargs 列表 |
| device | device | None | 放置 DataLoaders 的设备 |
| drop_last | bool | None | 丢弃最后一个不完整的批次,默认为 shuffle 的值 |
| val_bs | int | None | 验证集批量大小,默认为 bs 的值 |
dls = dsets.partial_dataloaders(partial_n=32, bs=16)assert len(dls[0])==2
for batch in dls[0]:
assert len(batch[0])==16