from fastai.vision.all import *训练 Imagenette
深入探讨 fastai 在计算机视觉中的分层 API
此图总结了 fastai 库作为分层 API 的结构
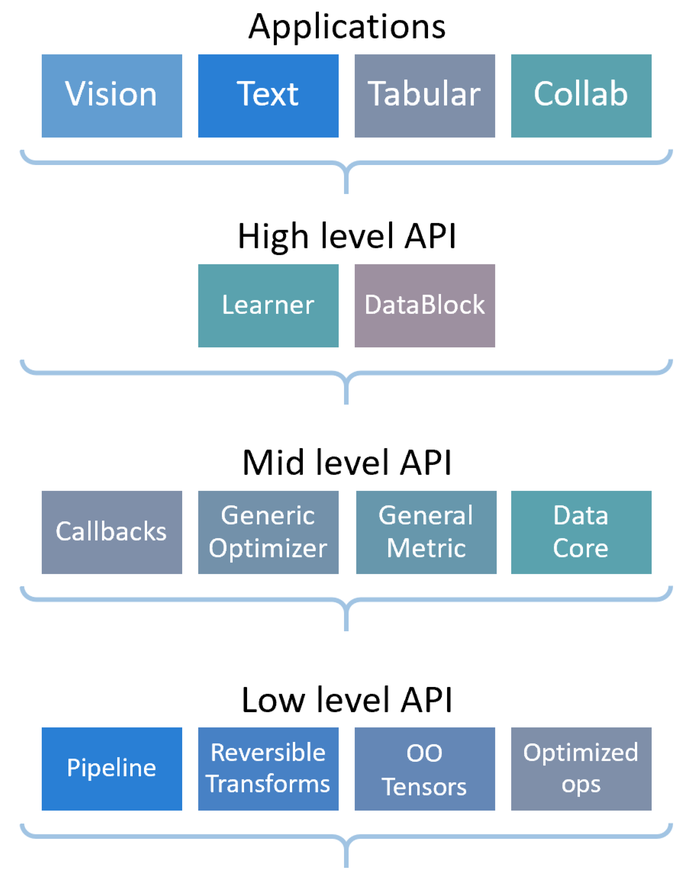
如果您正在阅读本教程,您可能已经熟悉这些应用了。在这里,我们将看到它们如何由高级和中级 API 提供支持。
Imagenette 是 ImageNet 的一个子集,包含 10 个差异很大的类别。在尝试将成熟的技术应用于完整的 ImageNet 数据集之前,它非常适合用于快速实验。本教程将展示如何使用常用的高级 API 在 Imagenette 上训练模型,然后深入 fastai 库内部,向您展示如何使用我们设计的中级 API。通过这种方式,您可以根据需要自定义数据收集或训练。
整理数据
我们将探讨几种将数据载入 DataLoaders 的方法:首先我们将使用 ImageDataLoaders 工厂方法(应用层),然后使用数据块 API(高级 API),最后使用中级 API 完成相同的事情。
使用工厂方法加载数据
这是我们在所有初级教程中都介绍过的最基本的数据组织方式,希望您现在已经熟悉它了。
首先,我们导入视觉应用中的所有内容
然后下载数据集并解压(如果需要),并获取其位置
path = untar_data(URLs.IMAGENETTE_160)
100.01% [99008512/99003388 01:15<00:00]
我们使用 ImageDataLoaders.from_folder 来获取所有数据(因为我们的数据是以 ImageNet 风格的格式组织的)
dls = ImageDataLoaders.from_folder(path, valid='val',
item_tfms=RandomResizedCrop(128, min_scale=0.35), batch_tfms=Normalize.from_stats(*imagenet_stats))然后我们可以查看我们的数据
dls.show_batch()
使用数据块 API 加载数据
正如我们在之前的教程中看到的,get_image_files 函数有助于获取子文件夹中的所有图像
fnames = get_image_files(path)让我们从一个空的 DataBlock 开始。
dblock = DataBlock()本质上,DataBlock 只是关于如何组织数据的蓝图。除非您为其传递一个源,否则它不会执行任何操作。然后,您可以使用 DataBlock.datasets 或 DataBlock.dataloaders 方法将该源转换为 Datasets 或 DataLoaders。由于我们还没有做任何准备工作将数据用于批处理,dataloaders 方法在这里会失败,但我们可以看看它如何转换为 Datasets。在这里,我们传递数据源,也就是所有的文件名。
dsets = dblock.datasets(fnames)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'),
Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03425413/n03425413_7416.JPEG'))默认情况下,数据块 API 假设我们有一个输入和一个目标,这就是为什么我们看到文件名重复了两次。
我们可以做的第一件事是使用 get_items 函数将我们的项目实际组织到数据块中
dblock = DataBlock(get_items = get_image_files)区别在于您将包含图像的文件夹而不是所有文件名作为源传递
dsets = dblock.datasets(path)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03888257/n03888257_42.JPEG'),
Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03888257/n03888257_42.JPEG'))我们的输入已准备好作为图像进行处理(因为图像可以从文件名构建),但我们的目标还没有。我们需要将文件名转换为类名。为此,fastai 提供了 parent_label
parent_label(fnames[0])'n03417042'这不是很易读,所以既然我们可以创建我们想要的函数,让我们将这些模糊的标签转换为我们可以读懂的东西
lbl_dict = dict(
n01440764='tench',
n02102040='English springer',
n02979186='cassette player',
n03000684='chain saw',
n03028079='church',
n03394916='French horn',
n03417042='garbage truck',
n03425413='gas pump',
n03445777='golf ball',
n03888257='parachute'
)def label_func(fname):
return lbl_dict[parent_label(fname)]然后我们可以通过将其作为 get_y 传递来告诉我们的数据块使用它来标记我们的目标
dblock = DataBlock(get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path)
dsets.train[0](Path('/home/jhoward/.fastai/data/imagenette2-160/train/n03000684/n03000684_8368.JPEG'),
'chain saw')现在我们的输入和目标都已准备好,我们可以指定类型来告诉数据块 API 我们的输入是图像而我们的目标是类别。在数据块 API 中,类型由块表示,这里我们使用 ImageBlock 和 CategoryBlock
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func)
dsets = dblock.datasets(path)
dsets.train[0](PILImage mode=RGB size=187x160, TensorCategory(0))我们可以看到 DataBlock 如何自动添加打开图像所需的转换,或者如何将名称“cassette player”更改为索引 2(带有特殊的张量类型)。为此,它创建了一个从类别到索引的映射,称为“词汇表”(vocab),我们可以通过这种方式访问它
dsets.vocab['English springer', 'French horn', 'cassette player', 'chain saw', 'church', 'garbage truck', 'gas pump', 'golf ball', 'parachute', 'tench']请注意,您可以随意组合任何块作为输入和目标,这就是该 API 被命名为数据块 API 的原因。您也可以拥有两个以上的块(如果您有多个输入和/或目标),只需将 n_inp 传递给 DataBlock,以告诉库有多少输入(其余的是目标),并将一个函数列表传递给 get_x 和/或 get_y(以解释如何处理每个项目使其适合其类型)。请参阅下面的对象检测示例。
下一步是控制如何创建验证集。我们通过将 splitter 传递给 DataBlock 来实现这一点。例如,这是我们按祖父文件夹进行分割的方法。
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = GrandparentSplitter())
dsets = dblock.datasets(path)
dsets.train[0](PILImage mode=RGB size=213x160, TensorCategory(5))最后一步是指定项目转换和批次转换(与我们在 ImageDataLoaders 工厂方法中做的方式相同)
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = label_func,
splitter = GrandparentSplitter(),
item_tfms = RandomResizedCrop(128, min_scale=0.35),
batch_tfms=Normalize.from_stats(*imagenet_stats))通过该 resize,我们现在能够将项目批量处理,最终可以调用 dataloaders 将我们的 DataBlock 转换为 DataLoaders 对象
dls = dblock.dataloaders(path)
dls.show_batch()
另一种组合 get_y 的多种函数的方法是将它们放入 Pipeline 中
imagenette = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = Pipeline([parent_label, lbl_dict.__getitem__]),
splitter = GrandparentSplitter(valid_name='val'),
item_tfms = RandomResizedCrop(128, min_scale=0.35),
batch_tfms = Normalize.from_stats(*imagenet_stats))dls = imagenette.dataloaders(path)
dls.show_batch()
要了解有关数据块 API 的更多信息,请查看数据块教程!
使用中级 API 加载数据
现在让我们看看如何使用中级 API 加载数据:我们将学习 Transform 和 Datasets。开头与之前相同:我们下载数据并获取所有文件名
source = untar_data(URLs.IMAGENETTE_160)
fnames = get_image_files(source)我们应用于原始项目(此处为文件名)的每一个转换在 fastai 中都称为 Transform。它本质上是一个具有一些附加功能的函数
- 它可以根据接收的类型表现出不同的行为(这称为类型分派)
- 它通常会应用于元组的每个元素
通过这种方式,当您有一个像 resize 这样的 Transform 时,您可以将其应用于元组(图像,标签),它会调整图像大小但不会调整分类标签大小(因为没有针对类别的 resize 实现)。完全相同的转换应用于元组(图像,掩码)时,将使用双线性插值调整图像大小,并使用最近邻插值调整目标(掩码)大小。库就是这样实现在每个计算机视觉应用(分割、点定位或对象检测)中始终应用数据增强转换的。
此外,转换可以具有
- 在整个数据集(或整个训练集)上执行的 setup。这就是
Categorize自动构建词汇表的方式。 - 一个 decodes 方法,用于显示目的时可以撤消转换的操作(例如,
Categorize会将索引转换回类别)。
我们在这里不会深入探讨低级 API 的这些部分,但您可以查看宠物教程或更高级的Siamese 教程以获取更多信息。
要打开图像,我们使用 PILImage.create 转换。它将打开图像并将其转换为 fastai 类型 PILImage
PILImage.create(fnames[0])
同时,我们已经看到了如何使用 parent_label 和 lbl_dict 获取图像的标签
lbl_dict[parent_label(fnames[0])]'garbage truck'为了使它们成为在馈送给模型之前映射到索引的正确类别,我们需要添加 Categorize 转换。如果我们要直接应用它,我们需要给它一个 vocab(这样它就知道如何将字符串与整数关联)。我们已经看到可以使用 Pipeline 组合多个转换
tfm = Pipeline([parent_label, lbl_dict.__getitem__, Categorize(vocab = lbl_dict.values())])
tfm(fnames[0])TensorCategory(5)现在要构建我们的 Datasets 对象,我们需要指定
- 我们的原始项目
- 从原始项目构建我们输入的转换列表
- 从原始项目构建我们目标的转换列表
- 训练集和验证集的分割
现在我们除了分割之外什么都有了,我们可以这样构建它
splits = GrandparentSplitter(valid_name='val')(fnames)然后我们可以将所有这些信息传递给 Datasets。
dsets = Datasets(fnames, [[PILImage.create], [parent_label, lbl_dict.__getitem__, Categorize]], splits=splits)与之前相比,主要区别在于我们可以直接传递 Categorize 而无需传递 vocab:它会在 setup 阶段从训练数据(它从 items 和 splits 中得知)构建 vocab。让我们看一下第一个元素
dsets[0](PILImage mode=RGB size=213x160, TensorCategory(5))我们也可以使用我们的 Datasets 对象来表示它
dsets.show(dsets[0]);
现在,如果我们想从这个对象构建 DataLoaders,我们需要添加一些将在项目级别应用的转换。正如我们之前看到的,这些转换将分别应用于输入和目标,为每种类型使用适当的实现(这很可能是什么都不做)。
在这里我们需要
- 调整我们的图像大小
- 将它们转换为张量
item_tfms = [ToTensor, RandomResizedCrop(128, min_scale=0.35)]此外,我们还需要在批次级别应用一些转换,即
- 将图像中的 int 张量转换为 floats,并将每个像素除以 255
- 使用 imagenet 统计数据进行归一化
batch_tfms = [IntToFloatTensor, Normalize.from_stats(*imagenet_stats)]这两部分也可以按项目进行,但在完整批次上进行效率更高。
请注意,我们比数据块 API 有更多的转换:在那里无需考虑 ToTensor 或 IntToFloatTensor。这是因为数据块在涉及到您始终需要该类型的转换时,会附带默认的项目转换和批次转换。
将这些转换传递给 .dataloaders 方法时,相应的参数名称略有不同:item_tfms 传递给 after_item(因为它们在项目形成后应用),而 batch_tfms 传递给 after_batch(因为它们在批次形成后应用)。
dls = dsets.dataloaders(after_item=item_tfms, after_batch=batch_tfms, bs=64, num_workers=8)然后我们可以使用传统的 show_batch 方法
dls.show_batch()
训练
我们将从我们在视觉教程中使用的常用 vision_learner 函数开始,我们将看到如何在 fastai 中构建一个 Learner 对象。然后我们将学习如何定制
- 损失函数以及如何编写一个与 fastai 完全兼容的函数,
- 优化器函数以及如何使用 PyTorch 优化器,
- 训练循环以及如何编写一个基本的
Callback。
构建 Learner
正如我们所见,构建用于图像分类的 Learner 最简单的方法是使用 vision_learner。我们可以通过传递 pretrained=False 来指定我们不需要预训练模型(这里的目标是从头开始训练模型)
learn = vision_learner(dls, resnet34, metrics=accuracy, pretrained=False)然后我们可以像往常一样拟合我们的模型
learn.fit_one_cycle(5, 5e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 2.371458 | 1.981063 | 0.336815 | 00:07 |
| 1 | 2.185702 | 3.057348 | 0.299363 | 00:06 |
| 2 | 1.935795 | 8.318202 | 0.360255 | 00:06 |
| 3 | 1.651643 | 1.327140 | 0.566624 | 00:06 |
| 4 | 1.395742 | 1.297114 | 0.616815 | 00:06 |
这是一个开始。但是既然我们不使用预训练模型,为什么不使用不同的架构呢? fastai 提供了包含现代研究中所有技巧的 ResNet 模型版本。虽然在编写本教程时还没有使用这些模型的预训练模型,但我们当然可以在这里使用它们。为此,我们只需要使用 Learner 类。它至少需要我们的 DataLoaders 和一个 PyTorch 模型。在这里,我们可以使用 xresnet34,由于我们有 10 个类别,我们指定 n_out=10
learn = Learner(dls, xresnet34(n_out=10), metrics=accuracy)我们可以使用学习率查找器找到一个好的学习率
learn.lr_find()SuggestedLRs(valley=0.0004786300996784121)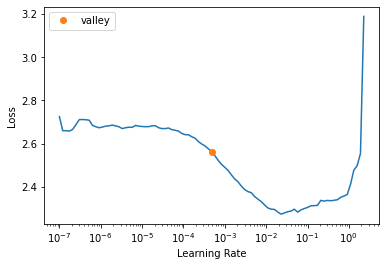
然后拟合我们的模型
learn.fit_one_cycle(5, 1e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 1.622614 | 1.570121 | 0.493758 | 00:06 |
| 1 | 1.171878 | 1.235382 | 0.593376 | 00:06 |
| 2 | 0.934658 | 0.914801 | 0.705987 | 00:06 |
| 3 | 0.762568 | 0.766841 | 0.754904 | 00:06 |
| 4 | 0.649679 | 0.675186 | 0.784204 | 00:06 |
哇,这是一个巨大的改进!正如我们在所有应用教程中看到的,然后我们可以使用以下方法查看一些结果:
learn.show_results()
现在让我们看看如何定制训练的每个部分。
更改损失函数
传递给 Learner 的损失函数期望接收输出和目标,然后返回损失值。它可以是任何常规的 PyTorch 函数,训练循环将正常工作。可能导致问题的是当您使用 fastai 函数时,例如 Learner.get_preds、Learner.predict 或 Learner.show_results。
如果您希望 Learner.get_preds 与参数 with_loss=True 一起工作(例如在运行 ClassificationInterpretation.plot_top_losses 时也会使用此参数),您的损失函数将需要一个 reduction 属性(或参数),您可以将其设置为“none”(这对于所有 PyTorch 损失函数或类来说都是标准的)。使用“none”的 reduction,损失函数不会返回一个单一的数值(如均值或总和),而是返回一个与目标大小相同的值。
至于 Learner.predict 或 Learner.show_results,它们内部依赖于您的损失函数应该具有的两个方法
- 如果您有一个结合了激活函数和损失函数(例如
nn.CrossEntropyLoss)的损失,需要一个activation函数。 - 一个
decodes函数,用于将您的预测转换为与您的目标相同的格式:例如,在nn.CrossEntropyLoss的情况下,decodes函数应该取 argmax。
举个例子,让我们看看如何实现一个执行标签平滑的自定义损失函数(fastai 中已经有 LabelSmoothingCrossEntropy)。
class LabelSmoothingCE(Module):
def __init__(self, eps=0.1, reduction='mean'): self.eps,self.reduction = eps,reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
if self.reduction=='sum': loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=-1) #We divide by that size at the return line so sum and not mean
if self.reduction=='mean': loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target.long(), reduction=self.reduction)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)我们不会评论仅实现损失本身的 forward 传递。重要的是要注意 reduction 属性在最终结果计算方式中的作用。
然后,由于这个损失函数结合了激活(softmax)和实际损失,我们实现了 activation 函数,它对输出取 softmax。这将使得 Learner.get_preds 或 Learner.predict 返回实际预测而不是最终激活值。
最后,decodes 通过取预测的 argmax,将模型的输出更改为与目标相同的格式(批次大小中的每个样本一个整数)。我们可以将此损失函数传递给 Learner
learn = Learner(dls, xresnet34(n_out=10), loss_func=LabelSmoothingCE(), metrics=accuracy)learn.fit_one_cycle(5, 1e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 1.734130 | 1.663665 | 0.521529 | 00:18 |
| 1 | 1.419407 | 1.358000 | 0.652994 | 00:19 |
| 2 | 1.239973 | 1.292138 | 0.675669 | 00:19 |
| 3 | 1.114046 | 1.093192 | 0.756688 | 00:19 |
| 4 | 1.019760 | 1.061080 | 0.772229 | 00:19 |
它的训练效果不如之前,因为标签平滑是一种正则化技术,所以需要更多周期才能真正发挥作用并给出更好的结果。
训练完模型后,我们确实可以使用 predict 和 show_results 并获得正确的结果
learn.predict(fnames[0])('garbage truck',
tensor(5),
tensor([1.5314e-03, 9.6116e-04, 2.7214e-03, 2.6757e-03, 6.4039e-04, 9.8842e-01,
8.1883e-04, 7.5840e-04, 1.0780e-03, 3.9759e-04]))learn.show_results()
更改优化器
fastai 使用其自己的 Optimizer 类,该类使用各种回调函数构建,以重构通用功能,并为扮演相同角色的超参数提供唯一的命名(例如 SGD 中的动量,它与 RMSProp 中的 alpha 和 Adam 中的 beta0 相同),这使得调度它们更加容易(例如在 Learner.fit_one_cycle 中)。
它实现了 PyTorch 支持的所有优化器(以及更多),因此您应该永远不需要使用来自 PyTorch 的优化器。请查看 optimizer 模块以查看所有 natively 可用的优化器。
然而,在某些情况下,您可能需要使用 fastai 中没有的优化器(例如,如果它是一个仅在 PyTorch 中实现的新优化器)。在学习如何将代码移植到我们的内部 Optimizer 之前(请查看 optimizer 模块了解如何操作),您可以使用 OptimWrapper 类来包装您的 PyTorch 优化器并使用它进行训练
pytorch_adamw = partial(OptimWrapper, opt=torch.optim.AdamW)我们编写一个优化器函数,它期望 param_groups,这是一个参数列表的列表。然后我们将这些传递给我们想要使用的 PyTorch 优化器。
我们可以使用这个函数并将其传递给 Learner 的 opt_func 参数
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))然后我们可以使用通常的学习率查找器
learn.lr_find()SuggestedLRs(lr_min=0.07585775852203369, lr_steep=0.00363078061491251)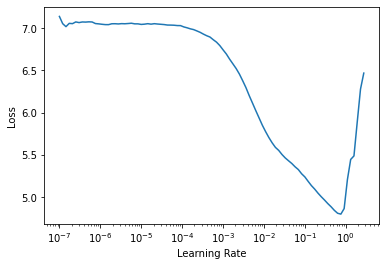
或 fit_one_cycle(多亏了包装器,fastai 将正确调度 AdamW 的 beta0)。
learn.fit_one_cycle(5, 5e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 2.661560 | 3.077346 | 0.332994 | 00:14 |
| 1 | 2.172226 | 2.087496 | 0.622675 | 00:14 |
| 2 | 1.913195 | 1.859730 | 0.695541 | 00:14 |
| 3 | 1.736957 | 1.692221 | 0.773758 | 00:14 |
| 4 | 1.631078 | 1.646656 | 0.788280 | 00:14 |
使用 Callback 更改训练循环
fastai 的基本训练循环与 PyTorch 相同
for xb,yb in dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()其中 model、loss_func 和 opt 都是我们 Learner 的属性。为了让您轻松地在该训练循环中添加新行为,而无需自己重写它(以及所有您可能需要的 fastai 组件,如混合精度、1cycle 调度、分布式训练等),您可以通过编写回调函数来定制训练循环中发生的事情。
Callback 将在后续教程中详细解释,但其基本原理是
- 一个
Callback可以读取Learner的每个部分,从而了解训练循环中发生的一切 - 一个
Callback可以更改Learner的任何部分,从而改变训练循环的行为 - 一个
Callback甚至可以引发特殊异常,允许设置断点(跳过一个步骤、一个验证阶段、一个周期,甚至完全取消训练)
在这里,我们将编写一个简单的 Callback 将 mixup 应用于我们的训练(我们将编写的版本特定于我们的问题,在其他设置中使用 fastai 的 MixUp)。
Mixup 包括通过混合两个不同的输入并对其进行线性组合来改变输入
input = x1 * t + x2 * (1-t)其中 t 是一个介于 0 和 1 之间的随机数。然后,如果目标是 one-hot 编码的,我们将目标更改为
target = y1 * t + y2 * (1-t)但在实践中,PyTorch 中的目标不是 one-hot 编码的,但更改损失函数处理 y1 和 y2 的部分等价于
loss = loss_func(pred, y1) * t + loss_func(pred, y2) * (1-t)因为使用的损失函数相对于 y 是线性的。
我们只需要使用损失函数中带有 reduction='none' 的版本来进行这种线性组合,然后取平均值。
以下是如何在 Callback 中编写 mixup
from torch.distributions.beta import Betaclass Mixup(Callback):
run_valid = False
def __init__(self, alpha=0.4): self.distrib = Beta(tensor(alpha), tensor(alpha))
def before_batch(self):
self.t = self.distrib.sample((self.y.size(0),)).squeeze().to(self.x.device)
shuffle = torch.randperm(self.y.size(0)).to(self.x.device)
x1,self.y1 = self.x[shuffle],self.y[shuffle]
self.learn.xb = (x1 * (1-self.t[:,None,None,None]) + self.x * self.t[:,None,None,None],)
def after_loss(self):
with NoneReduce(self.loss_func) as lf:
loss = lf(self.pred,self.y1) * (1-self.t) + lf(self.pred,self.y) * self.t
self.learn.loss = loss.mean()我们可以看到我们编写了两个事件
before_batch在绘制批次之后、模型在输入上运行之前执行。我们首先根据 beta 分布(如论文中所建议的)绘制随机数t,并获取批次的打乱版本(而不是绘制批次的第二个版本,我们将一个批次与其自身的打乱版本混合)。然后我们将self.learn.xb设置为新的输入,这将是馈送给模型的输入。after_loss在计算损失之后、反向传播之前执行。我们将self.learn.loss替换为正确的值。NoneReduce是一个上下文管理器,它临时将损失的 reduction 属性设置为“none”。
此外,我们通过 run_valid=False 告诉 Callback 在验证阶段不运行。
要将 Callback 传递给 Learner,我们使用 cbs=
learn = Learner(dls, xresnet18(), lr=1e-2, metrics=accuracy,
loss_func=LabelSmoothingCrossEntropy(), cbs=Mixup(),
opt_func=partial(pytorch_adamw, weight_decay=0.01, eps=1e-3))然后我们可以将这个新的回调与学习率查找器结合使用
learn.lr_find()SuggestedLRs(lr_min=0.06309573650360108, lr_steep=0.004365158267319202)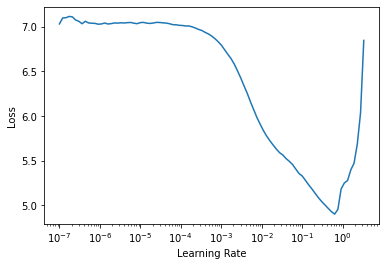
并将其与 fit_one_cycle 结合使用
learn.fit_one_cycle(5, 5e-3)| 周期 | 训练损失 | 验证损失 | 准确率 | 时间 |
|---|---|---|---|---|
| 0 | 3.094243 | 3.560097 | 0.175796 | 00:15 |
| 1 | 2.766956 | 2.633007 | 0.400000 | 00:15 |
| 2 | 2.604495 | 2.454862 | 0.549809 | 00:15 |
| 3 | 2.513580 | 2.335537 | 0.598726 | 00:15 |
| 4 | 2.438728 | 2.277912 | 0.631338 | 00:15 |
与标签平滑一样,这是一个提供更多正则化的回调函数,因此您需要运行更多周期才能看到任何好处。此外,我们的简单实现没有 fastai 实现的所有技巧,因此请务必查看 callback.mixup 中的官方版本!